Keywords AI
By February 2025, the race to build the best coding-focused large language model (LLM) has never been fiercer. New entrants like DeepSeek R1 and OpenAI o1/o3 are pushing the boundaries of reasoning, while established names such as Anthropic, Google, Meta, and QWen remain major contenders.
With so many models to choose from, developers can feel overwhelmed.
But how can you choose the best LLM for your coding use case?
This blog explores the top benchmarks you can use to evaluate coding LLMs and choose the best one for your specific needs.
TL;DR
-
- Chatbot Arena Leaderboard – Popular vote-based rankings across all LLMs, including coding.
-
- HumanEval – Focuses on functional correctness in code generation.
-
- Big Code Models Leaderboard – Open-source, multilingual code generation benchmarks.
-
- CanAiCode Leaderboard – Real-world interview-style coding questions across multiple levels.
-
- The Polyglot Benchmark – Evaluates code editing and integration in multiple languages.
-
- StackEval – Assesses practical coding assistance quality using StackOverflow questions.
Chatbot Arena LLM Leaderboard
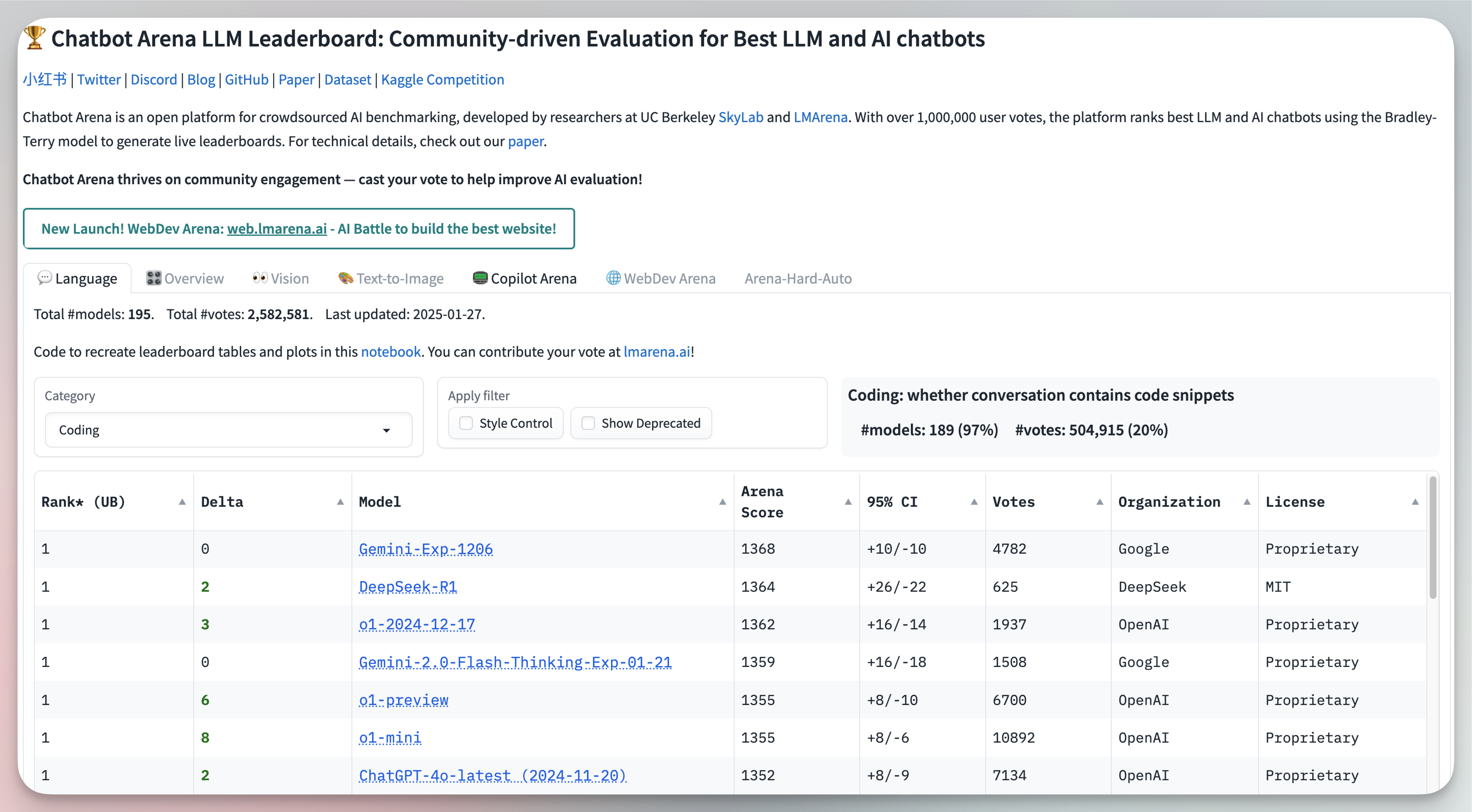
The Chatbot Arena LLM Leaderboard relies on votes from thousands of developers, making it one of the most visited coding LLM resources. Because all rankings are user-generated, it offers valuable insights into what developers find most helpful but can sometimes be skewed by personal preferences or trends. Despite the potential bias, it remains an excellent starting point for anyone wanting a quick overview of coding LLM performance in real-world settings.
HumanEval
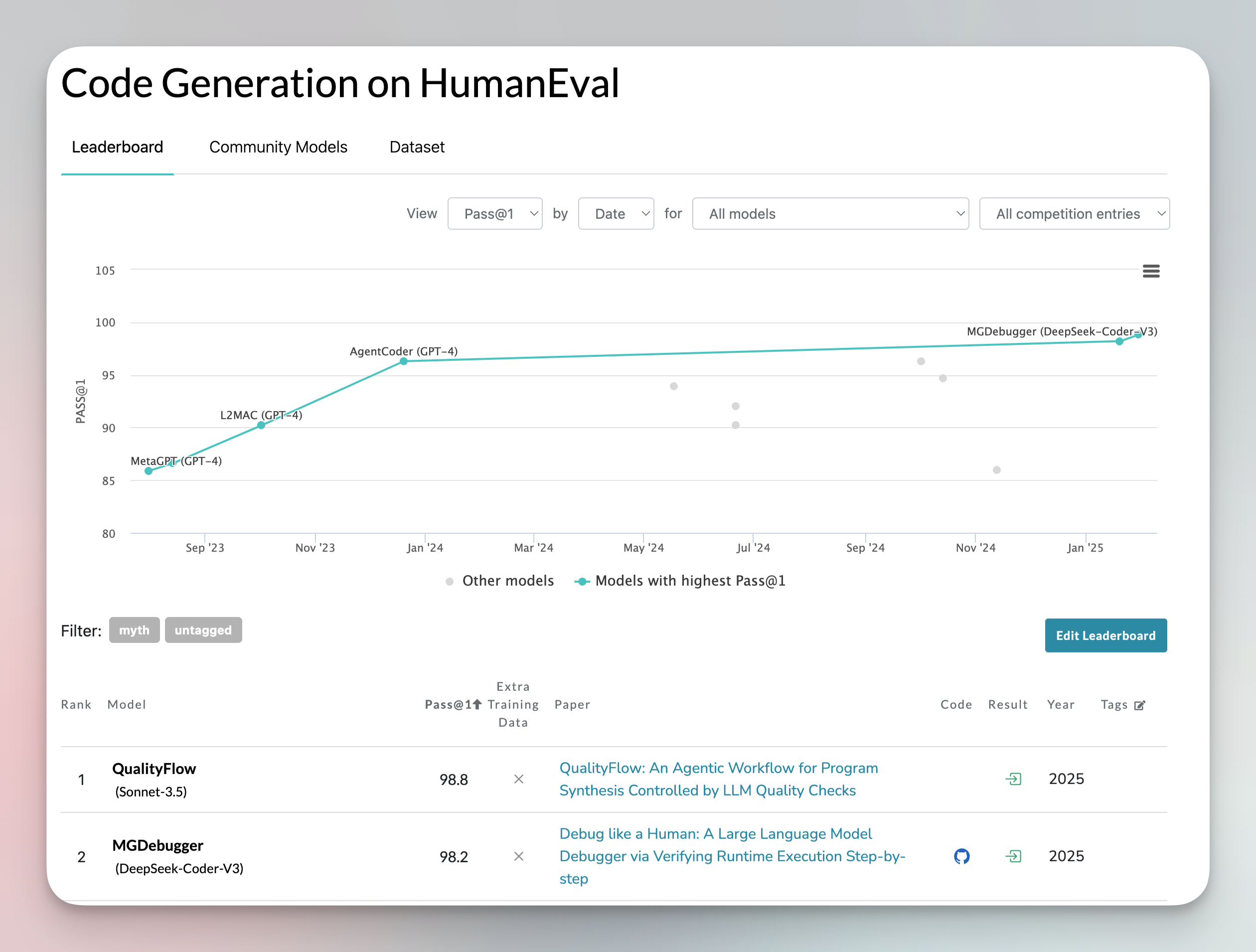
HumanEval is a benchmark dataset designed to evaluate how effectively large language models (LLMs) generate code. It was developed by OpenAI.
Here’s what it does:
- Compares the performance of different LLMs in code generation
- Assesses the functional correctness of the generated code
- Provides a standardized set of challenges for all models to solve
However, HumanEval has some limitations. It shows a significant bias toward a narrow range of programming concepts, leaving many underrepresented or excluded. This can lead to overestimating a model’s performance in real-world coding tasks.
Additionally, HumanEval includes only a limited number of LLMs, so smaller open-source coding models are often missing from this benchmark.
Big Code Models Leaderboard
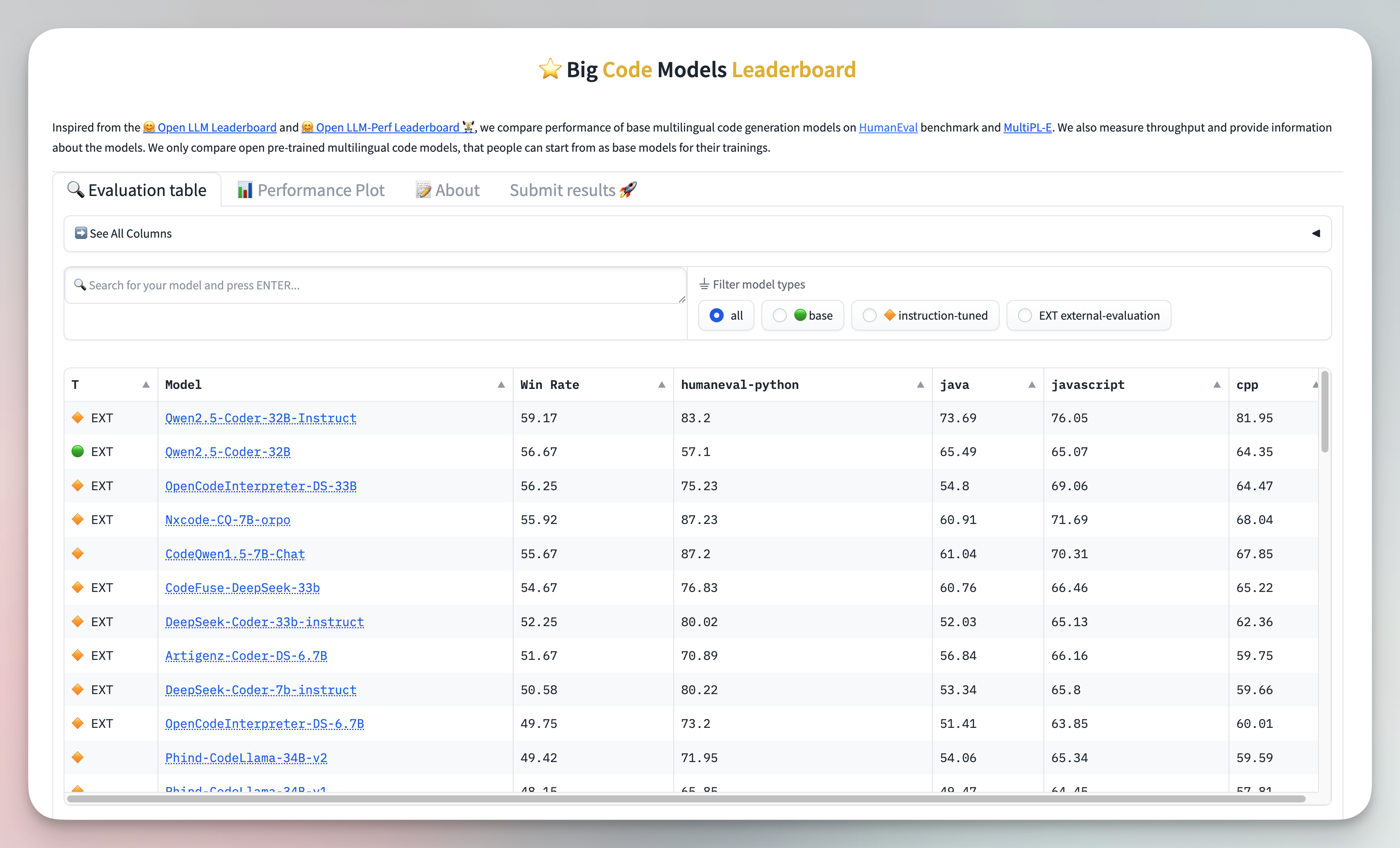
The Big Code Models Leaderboard evaluates the performance of multilingual code generation models using benchmarks like HumanEval and MultiPL-E. It also measures throughput and provides detailed information about the models.
However, this benchmark focuses exclusively on open, pre-trained multilingual code models. These models serve as starting points for further training or customization.
One of its strengths is the comprehensive ranking it provides across various programming languages, offering developers a clear view of how models perform in different coding contexts.
While it’s a valuable resource for open-source multilingual models, it does not include closed-source or specialized models, which may limit its scope for some users.
CanAiCode Leaderboard
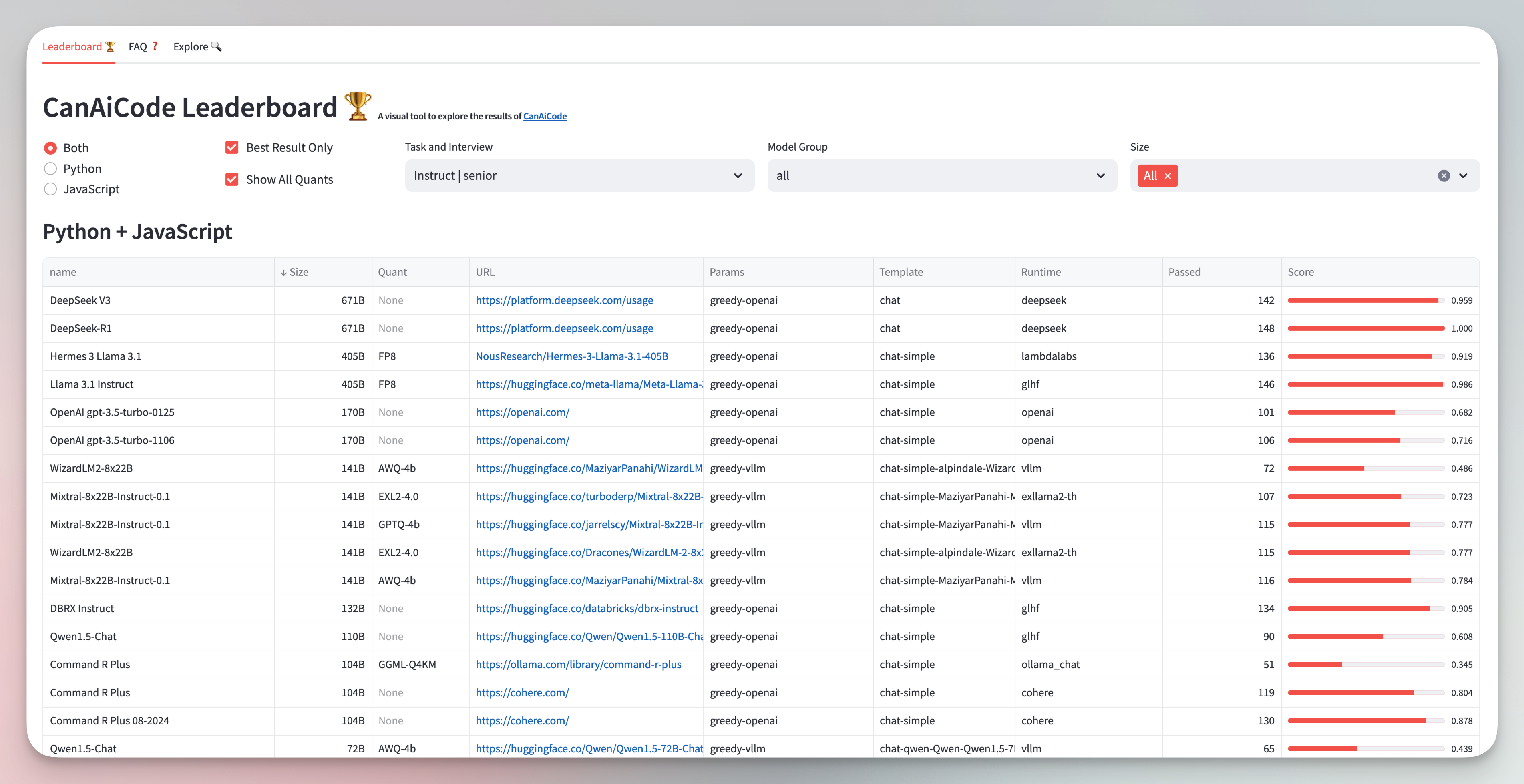
The CanAiCode Leaderboard is a highly useful yet underrated benchmark. It features a wide range of interview questions created by humans and tested by AI, making it highly relevant to real-world scenarios. This benchmark effectively addresses practical problems that developers face in their work.
The structure is well-organized, with datasets spanning from junior to senior-level difficulty. It includes nearly every coding LLM on the market, such as CodeLlama, DeepSeek-coder, and WizardCoder.
One of its standout features is the detailed results and rankings it provides for Python and JavaScript, offering developers clear insights into model performance in these widely-used languages.
The Polyglot Benchmark

The Polyglot Benchmark, part of the Aider LLM Leaderboards, tests how well LLMs edit and integrate code across multiple languages. It uses 225 of the most challenging Exercism exercises in C++, Go, Java, JavaScript, Python, and Rust to evaluate models’ ability to write and apply code changes without human intervention.
This benchmark is ideal for developers who need LLMs to handle complex, real-world coding tasks. Unlike earlier Python-focused benchmarks, it offers a broader, more rigorous evaluation. Models like DeepSeek R1 and OpenAI o1 have already been tested, providing insights into their strengths and limitations in advanced coding scenarios.
StackEval
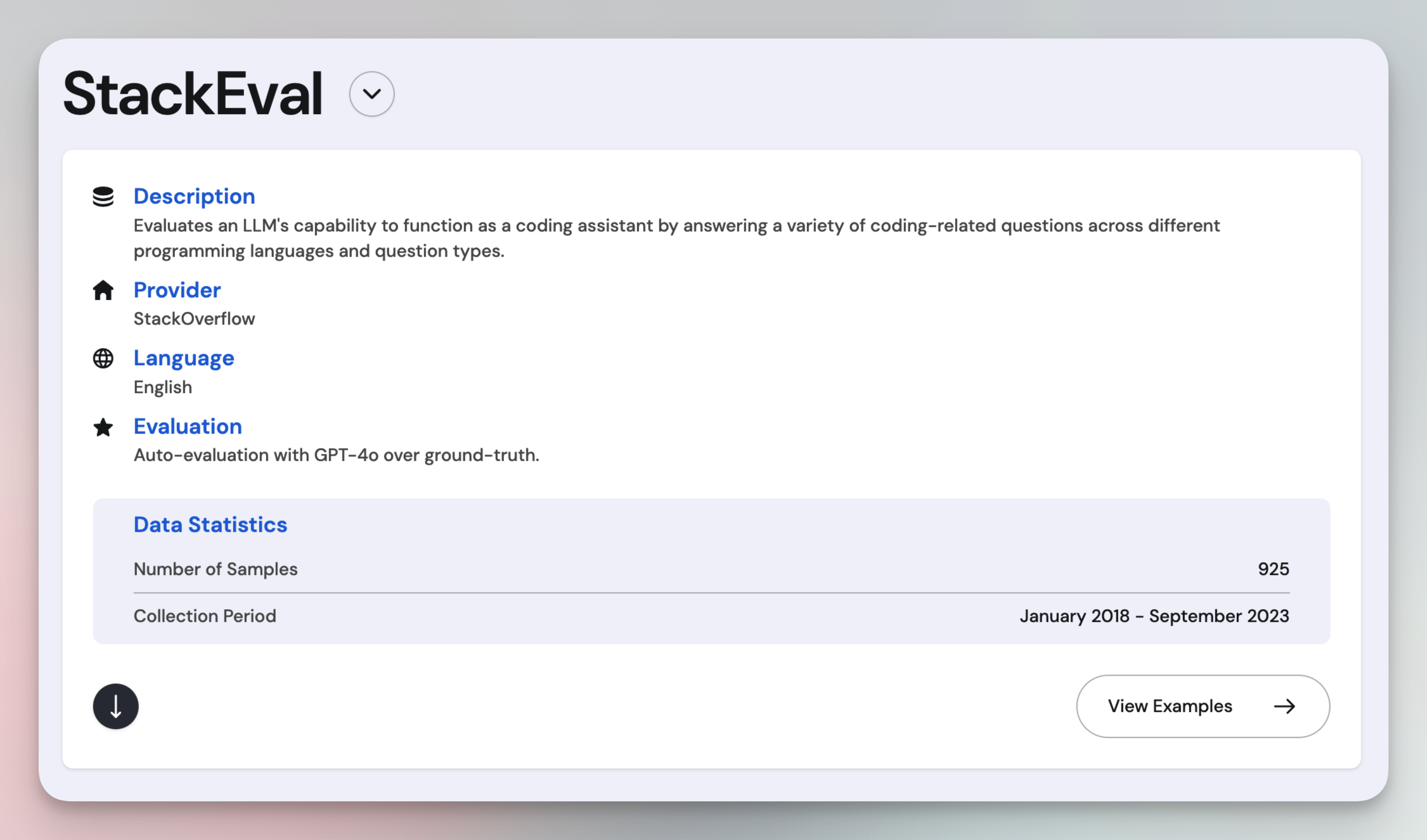
StackEval evaluates an LLM’s ability to function as a coding assistant by testing its responses to real-world coding questions sourced from StackOverflow. It ranks models based on Acceptance Rate, which measures how well an answer meets the user’s needs and resolves their issue.
To be acceptable, a response must be accurate, relevant, and complete—providing a viable solution without requiring further edits. For example, if the answer includes a code snippet, it must run flawlessly.
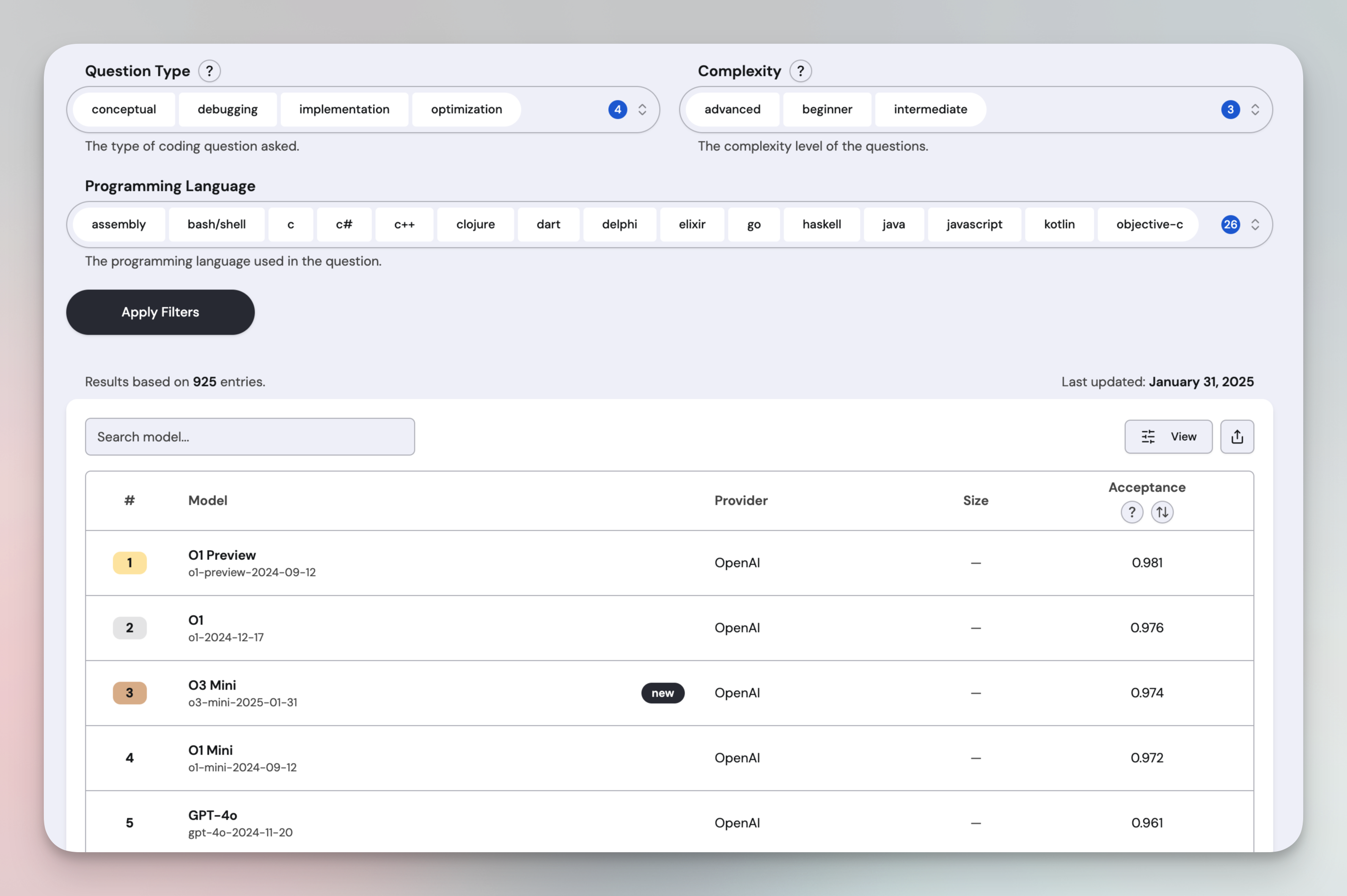
The benchmark covers four question types: Conceptual, Debugging, Implementation, and Optimization, with complexity levels ranging from Beginner to Advanced. It also includes 26 programming languages, making it a versatile tool for finding the best coding LLM for any language.
Final thoughts
Choosing the right coding LLM in 2025 requires sifting through a complex array of options. These six benchmarks—ranging from community-driven vote tallies to more specialized evaluations—offer a clear path to understanding how models perform in different scenarios. By focusing on the benchmarks that align with your specific needs, you can find an LLM that truly excels at the tasks that matter most to you.


