Keywords AI
September 12, 2025
Improved LLM log exports
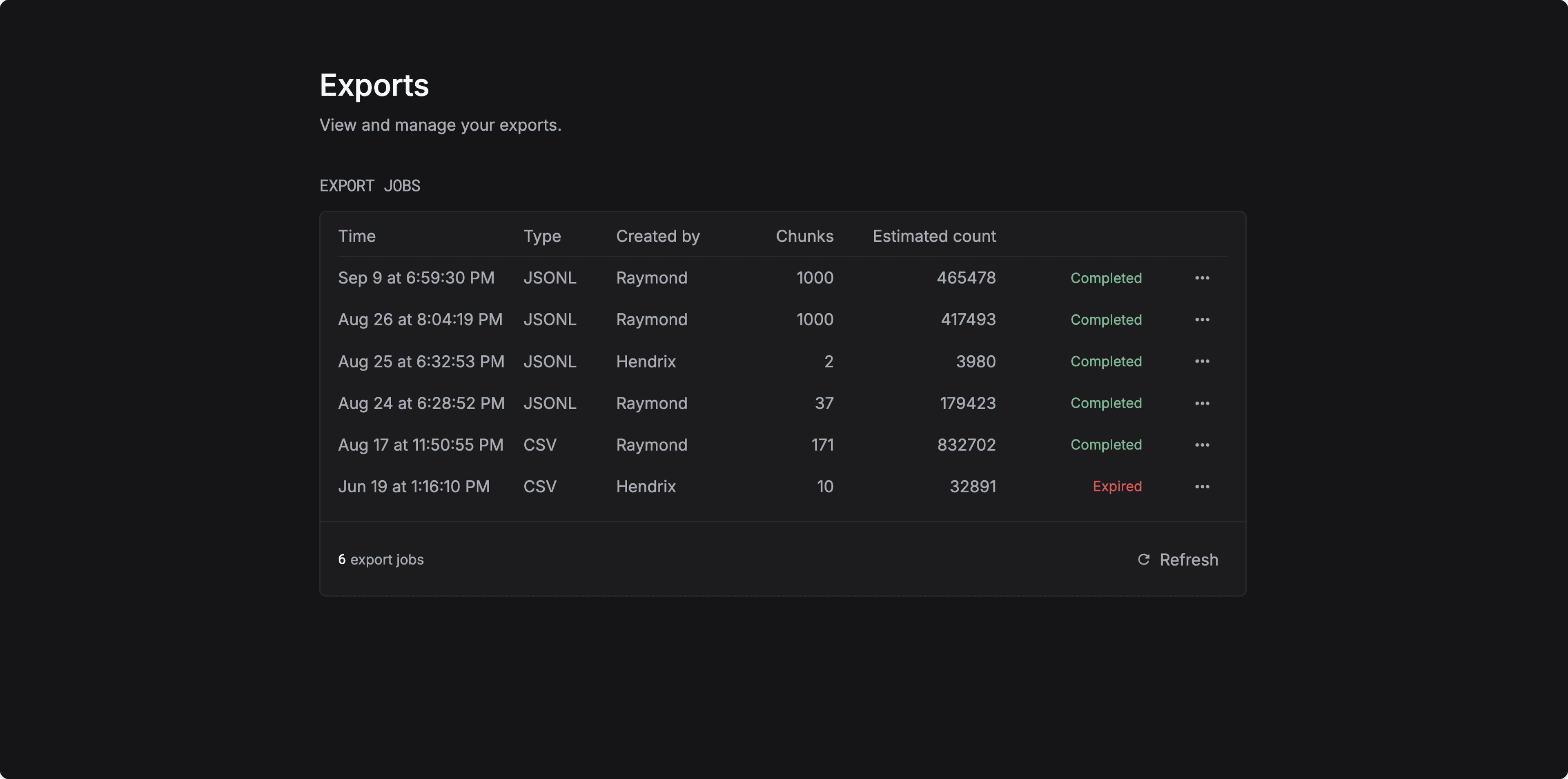
We’ve made exports faster and more reliable.
You can now export large volumes of LLM logs in JSONL or CSV format within minutes.
This makes it simple to move your LLM data to fine-tuning platforms and train your own models.
September 5, 2025
Labels for Testsets
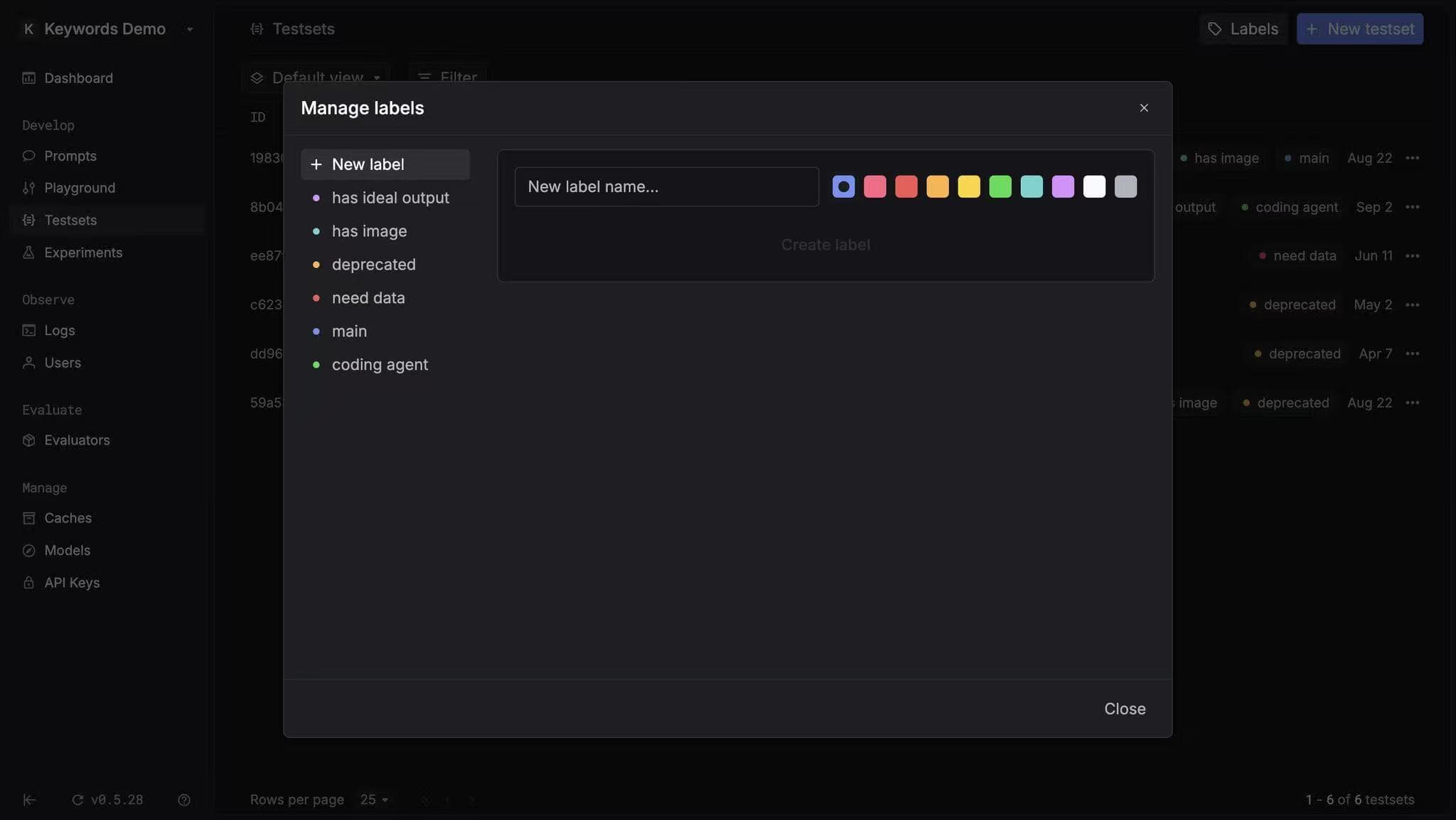
You can now add labels to your testsets!
This makes it easier to organize, manage, and find the right testset - especially when you have hundreds.
August 8, 2025
GPT-5 is here!

We’ve all been waiting for OpenAI’s GPT-5, and it’s finally here. We added GPT-5 to Keywords AI within minutes. You can try it out now in our Playground, or use our AI gateway to call it directly in your code.
August 1, 2025
Light mode
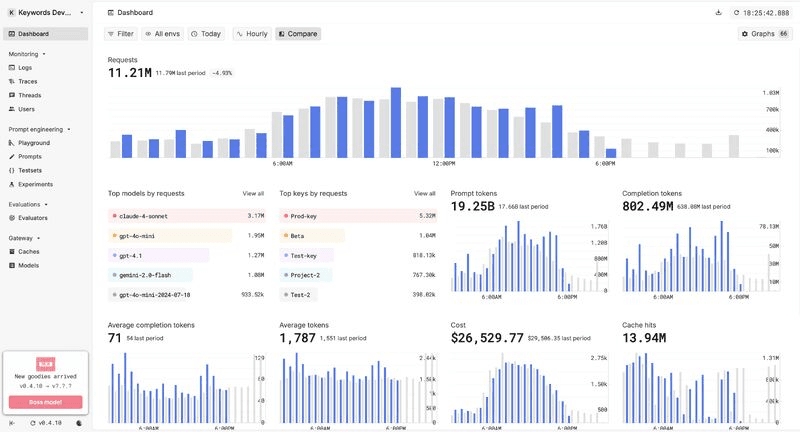
NEW: Light mode is here.
We just rolled out the beta version of our light theme!
It’s clean, fast, and designed to make monitoring, prompt management, and evals even easier on the eyes.
Give it a spin and let us know what you think.
July 18, 2025
Limits for your LLM usage.
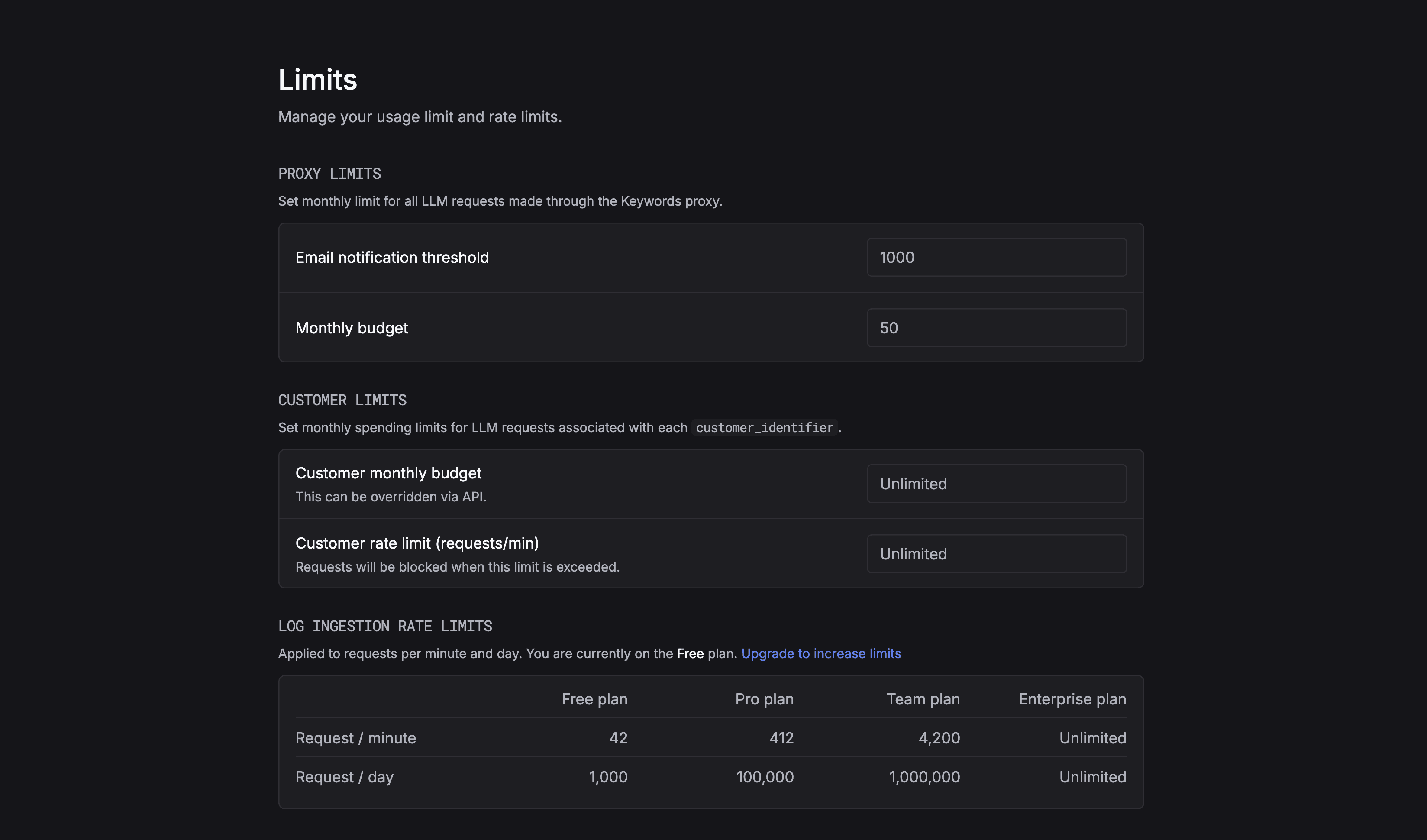
You can now set limits for your LLM usage and get notified when you're approaching the threshold.
This is useful if you want to avoid unexpected costs or if you want to limit your usage to a certain amount.
You can set the limit in the Settings page.
July 11, 2025
Improvements to the LLM Usage Dashboard
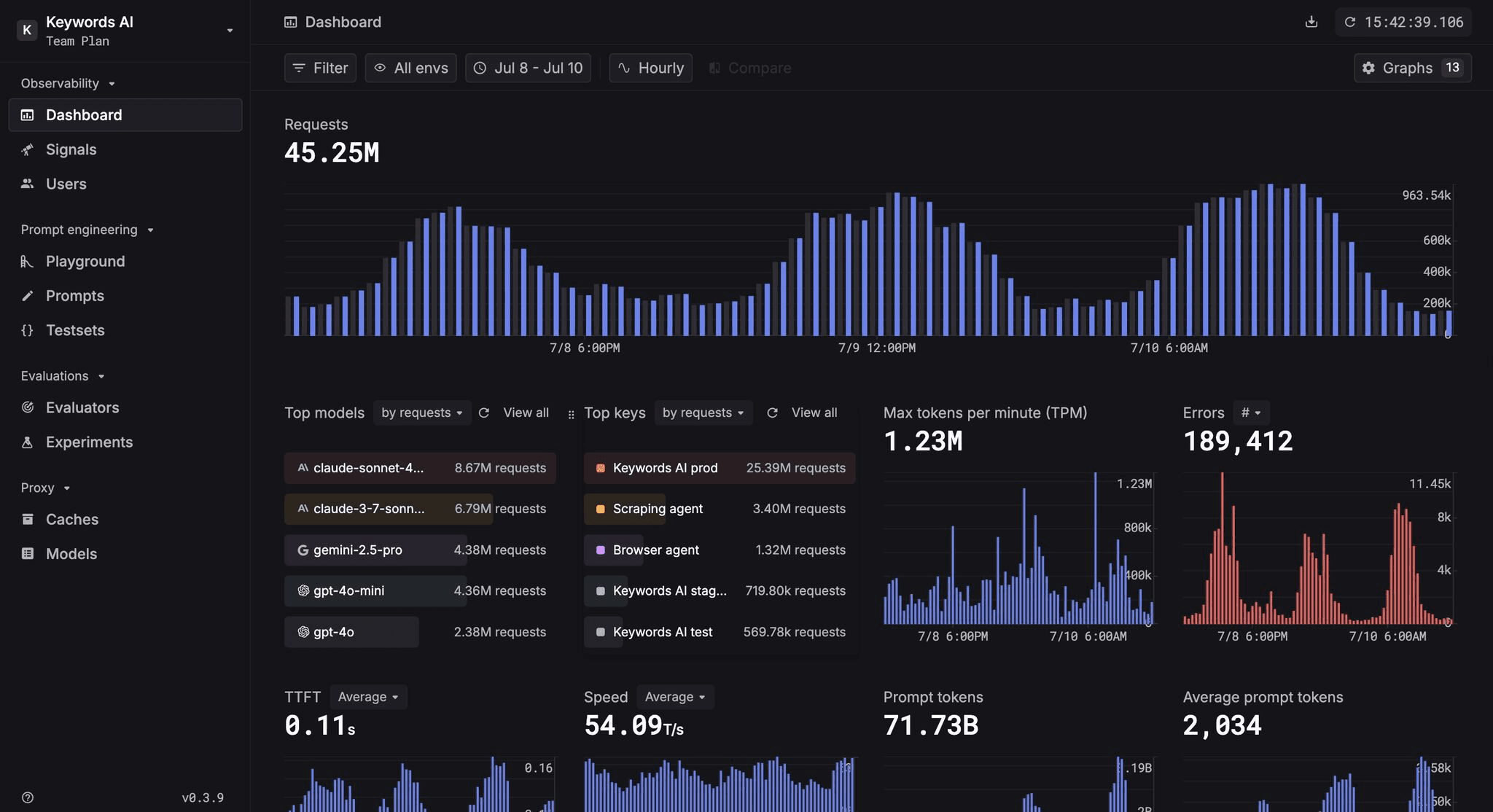
As one of the most visited pages on Keywords AI, the dashboard plays a key role in helping developers monitor and debug their LLM usage.
We’ve made several updates to improve performance and UX:
- •10x smoother performance for bar and line charts
- •Grids added to graphs for clearer number reading
- •Improved categorization for selecting graphs
- •Enhanced calendar for better time filtering
July 4, 2025
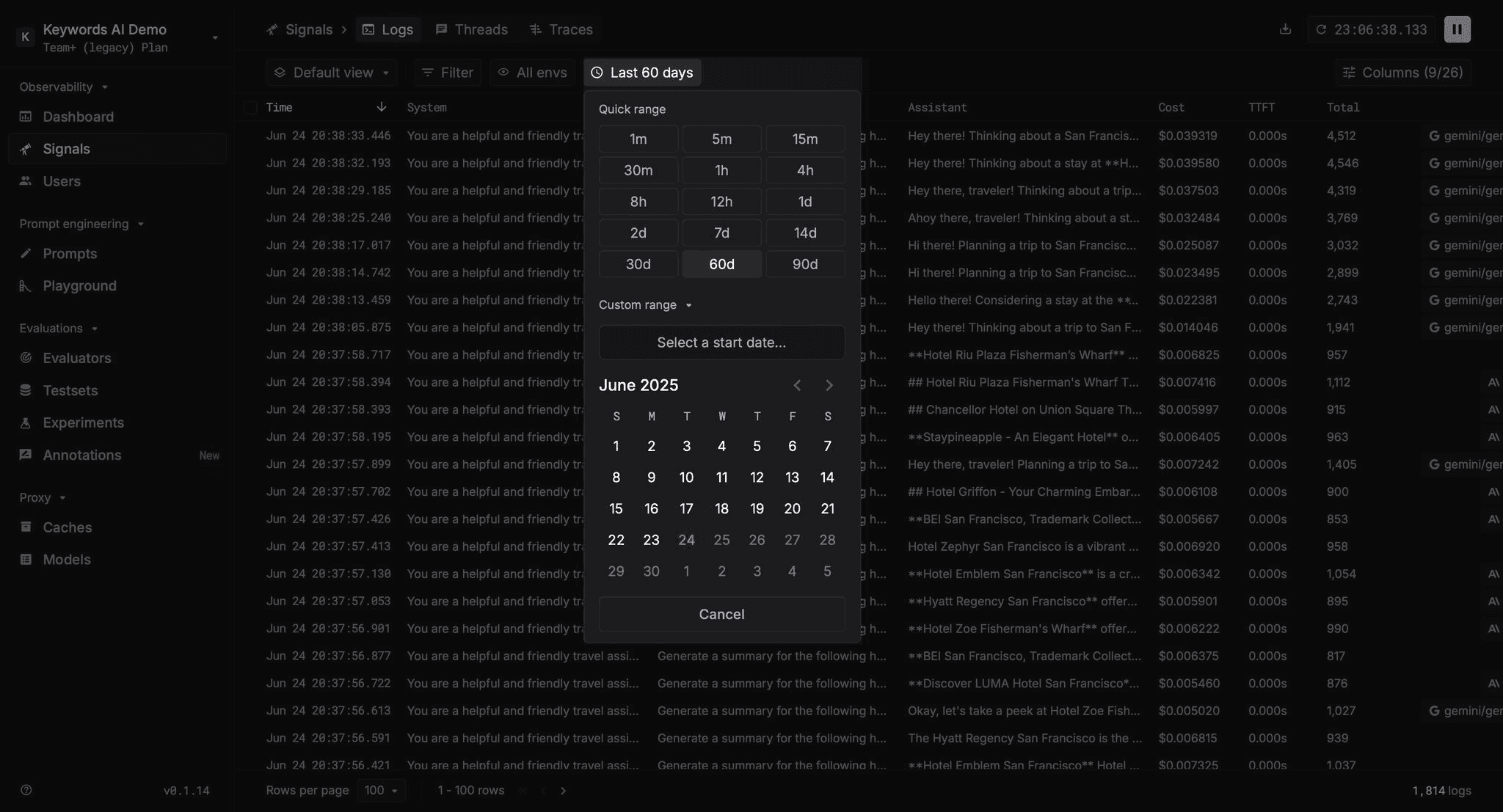
Custom date range for LLM log filtering
More AI apps are using images alongside text — especially agents like QA bots, browser agents, or travel assistants.
But most prompt testing tools only support text.
If your dataset includes images (e.g. product photos, screenshots, or hotel pictures), you are stuck.
Now you can upload datasets with image URLs as columns, just like any other variable — and test how your prompts perform with both text and image inputs.
June 27, 2025
Support for image inputs in Experiments
More AI apps are using images alongside text — especially agents like QA bots, browser agents, or travel assistants.
But most prompt testing tools only support text.
If your dataset includes images (e.g. product photos, screenshots, or hotel pictures), you are stuck.
Now you can upload datasets with image URLs as columns, just like any other variable — and test how your prompts perform with both text and image inputs.
June 20, 2025
Actions for LLM logs
Working with LLM logs just got easier. Now you can handle common tasks in one place:
• Share logs with your team for debugging
• Re-run requests to test prompts
• Save real-world examples to your testset
• Create new prompts from existing logs
Simply click "Actions" in the side panel and choose what you need. All your LLM log actions are now in one convenient spot.
June 13, 2025
Create prompt from log
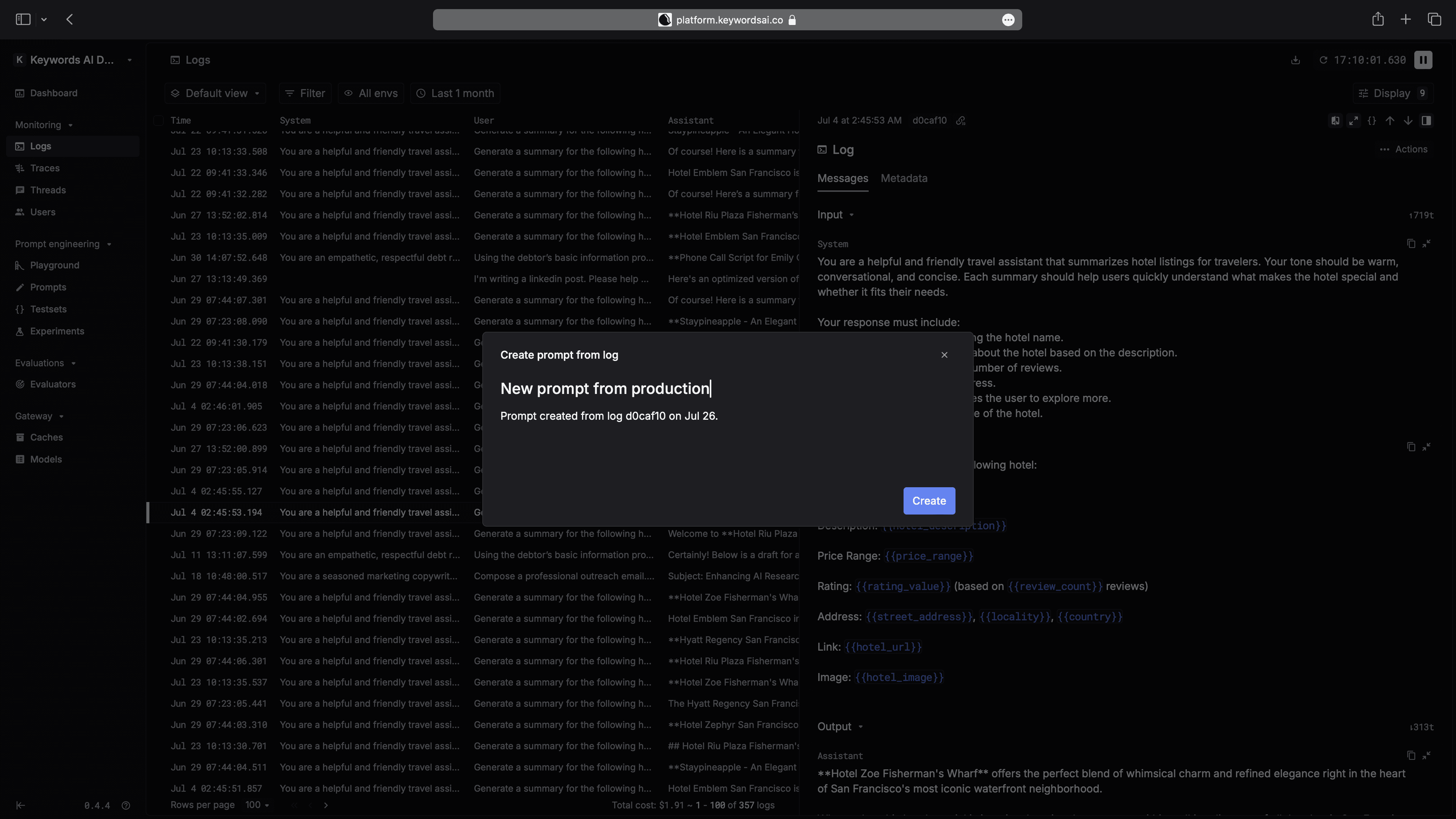
You can now create a new prompt from an LLM log. Simply click "Actions" in the side panel and choose "create prompt".
June 6, 2025
Introducing Signals

We just merged Logs, Threads, and Traces into a single Signals page.
Following the OpenTelemetry convention, Signals unifies different types of observability data — so you can investigate LLM logs, traces, and threads without switching tabs.
One clean view to understand everything happening in your LLM workflow.
May 30, 2025
LLM Cache Metrics Graphs
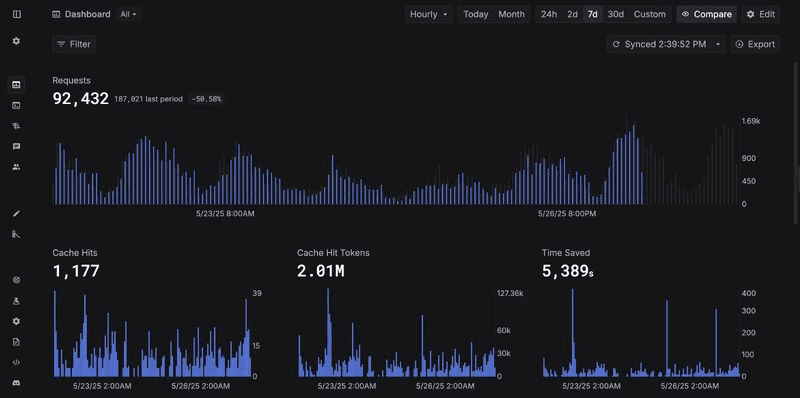
We’ve just shipped new graphs that show your LLM caching details!
When you enable LLM caching with Keywords AI Gateway, cache metrics appear automatically in your dashboard.
Why use Keywords AI LLM caching?
✅ Reduce latency
✅ Save cost
✅ Improve scalability
May 23, 2025
Bar charts in Dashboard.
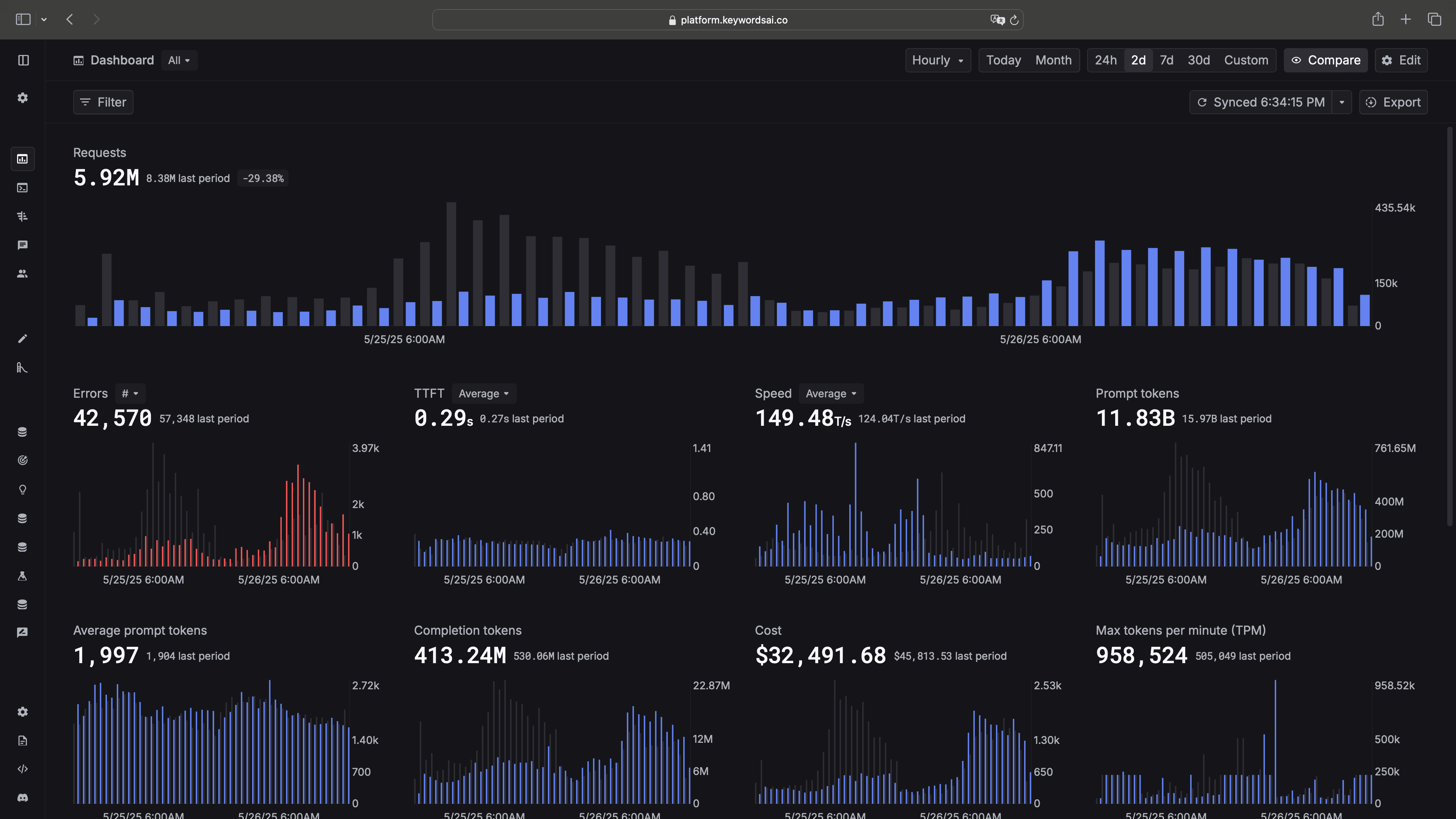
We just shipped bar charts to the Dashboard on Keywords AI (YC W24)!
Why bar charts?
Line graphs are great for trends, but when you're working with discrete time buckets — like hourly traffic or error counts — bar charts are much easier to read. You can quickly spot spikes, compare values, and get a clear sense of what's happening.
Some common use cases:
- •See traffic by hour more clearly
- •Catch error spikes at a glance
- •Understand how prompt and completion tokens change over time
You can turn it on in:
Settings → Preferences → Show bar chart
May 16, 2025
New graphs for monitoring LLM usage
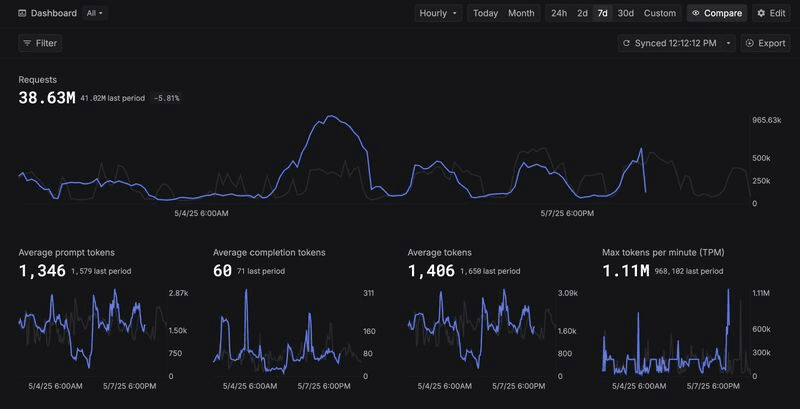
We’ve just released new graphs to help you track your LLM usage more easily:
- •Average prompt tokens
- •Average completion tokens
- •Average tokens
- •Max tokens per minute
These new graphs make it easier to spot trends, optimize performance, and manage costs.
Check them out and get a deeper understanding of your LLM activity!
May 9, 2025
Prompt version monitoring
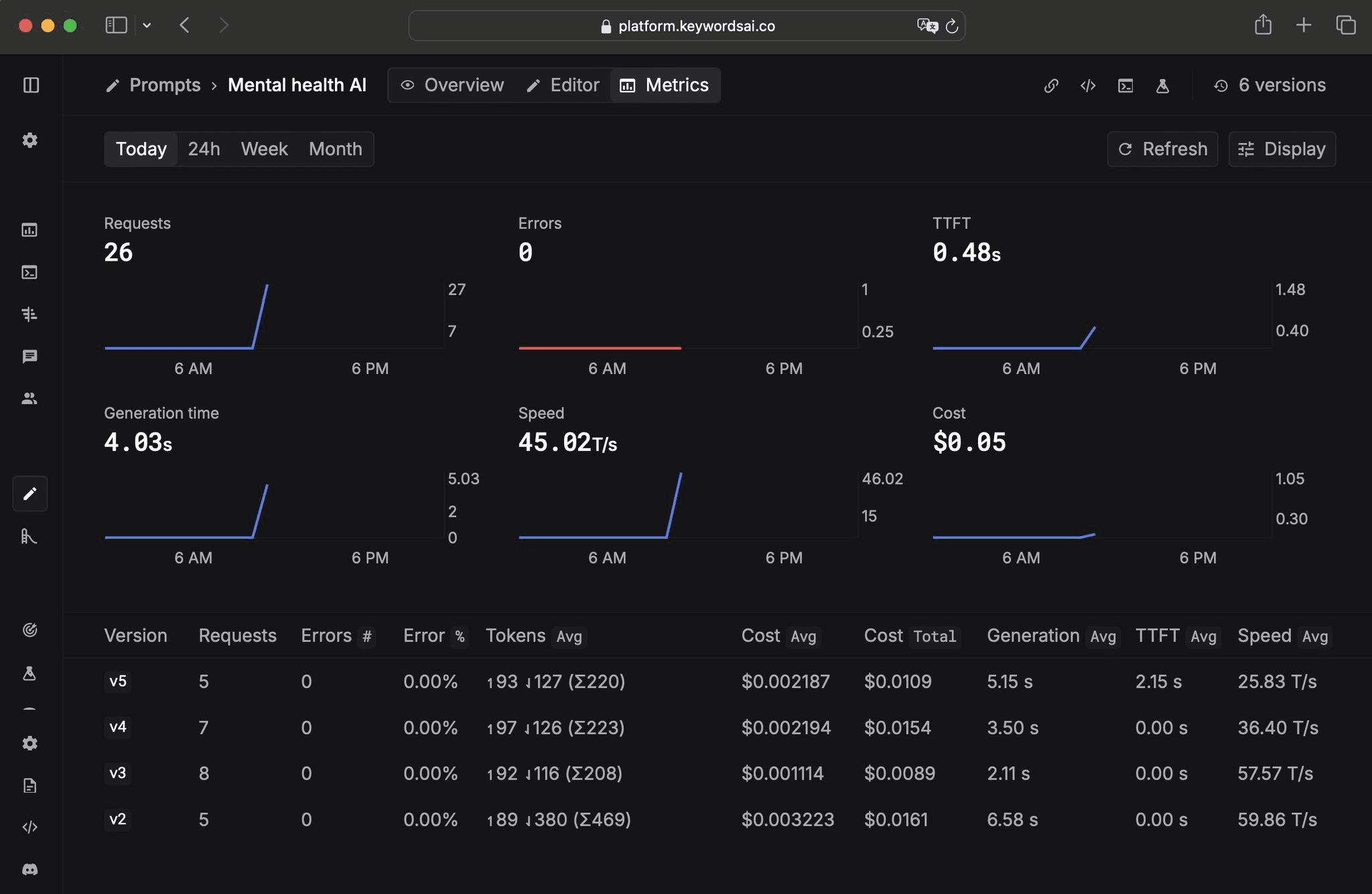
You can now track prompt versions by linking a prompt ID in your code and deploying new versions in the UI.
This helps you track the performance of each version, ensuring you're always using the best one.
We are making it easier to test, deploy, and improve prompts. Try it out today!
May 2, 2025
Draggable dashboard charts
You can now easily drag and rearrange dashboard charts to customize their layout just the way you want.
April 25, 2025
Redesigned prompt list UI
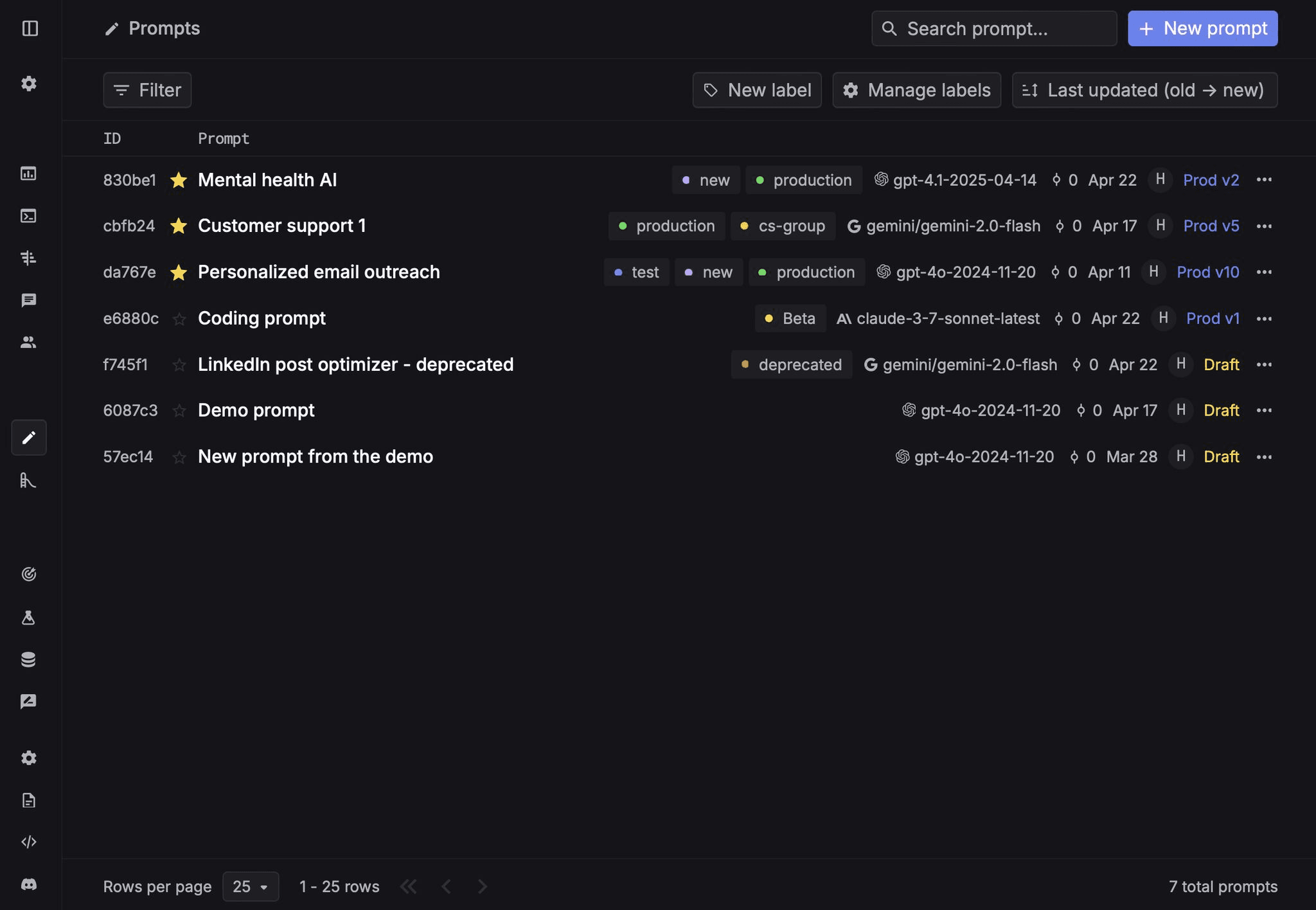
We’ve redesigned the prompt list UI to make managing prompts easier and more efficient.
Here’s what’s new:
- •🔍 Search for prompts seamlessly.
- •📝 View additional details, like version and model, without needing to click.
- •🎨 More colors for labels to improve organization.
We’re excited about these improvements and hope they make your workflow smoother!
April 18, 2025
New display modes in Experiments
We have added 3 display modes in Experiments.
Now, you can easily adjust the display height of each cell by switching between these modes.
April 11, 2025
Vercel AI SDK integration

If you're building AI agents with Vercel AI SDK, you can now easily add Keywords AI tracing to your Next.js project. This integration lets you clearly see what's happening inside your AI agents, from start to finish.
It takes less than 5 minutes to set up, is completely safe for your existing system, and gives you powerful insights to improve your AI performance.
April 4, 2025
New integration: OpenAI Responses API

The Responses API is OpenAI’s most advanced interface for generating model responses, unifying the best of Chat Completions and Assistants API.
Today, we're launching the support for the Responses API - making it easy for developers to set up LLM observability and evaluations with just a few lines of code.
March 28, 2025
Logs Side Panel UI Update
We redesigned the Logs side panel for improved readability and LLM debugging. The new interface allows for more efficient testing and refinement of LLM outputs.
March 21, 2025
Native integration for OpenAI Agents SDK
We worked with OpenAI to build a native integration for the OpenAI Agents SDK. Today, we are very excited to launch as a tracing processor.
With just a few lines of code, you can trace all your agent workflows and debug them much faster. Check out the quick demo here.
March 14, 2025
Run evaluations in Experiments

You can now run LLM evals in Experiments. Import the defined evaluators and then choose the evaluator you want to run for each cell.
March 7, 2025
Human, LLM, and Code Evaluations

We have redesigned Evaluations, allowing you to run human, LLM, and code evaluations in Keywords AI. Set up your first evaluator in minutes.
February 28, 2025
Jinja support in Prompts

We have introduced Jinja support in prompts, allowing you to use Jinja templates to create more dynamic prompts. For more details, visit the Jinja in Prompts page.