Keywords AI
Meet Inference.net – A Faster, Cheaper Way to Run Open-Source LLMs
Inference.net is a new open-source large language model (LLM) provider that makes it easy to harness powerful AI models with exceptional speed and cost-efficiency. It offers a global serverless inference platform, combining cloud-grade reliability with the flexibility of open-source AI. Whether you’re building a new app, scaling to enterprise workloads, or pushing forward in research, Inference.net provides a scalable, developer-friendly solution for LLM deployment.
Open-Source and Blazing Fast
One of Inference.net’s core strengths is its open-source foundation. Instead of proprietary black-box models, it supports popular open-source LLMs, giving you the freedom to choose and even customize the right model for your needs.
Backed by a distributed global GPU network, Inference.net also delivers blazing fast performance. Its serverless architecture scales from one request to millions, ensuring low latency even under heavy workloads. In short, you get cloud-level performance while using open models on your own terms.
Easy Integration with Popular Models
Inference.net is built with developers in mind. Its API is fully OpenAI-compatible, meaning you can switch an existing application to Inference.net with just a line or two of code. This seamless integration lets you plug in open-source models without learning a new interface.
The platform also works with popular libraries like LangChain, so you can incorporate advanced AI features with minimal friction. From chat and code generation to vision-and-language tasks, its model library covers the common use cases. Inference.net even offers $25 in free credits to get you started, allowing you to test and prototype at no cost.
Pricing: Performance on a Budget
Inference.net sets itself apart with transparent, pay-as-you-go pricing that can significantly reduce costs. You only pay for what you use, with rates up to 90% lower than many legacy providers. Here’s how it compares to other LLM inference services on a per-model basis:
| Model | Inference.net | Together AI | Fireworks AI |
|---|---|---|---|
| DeepSeek R1 | $3.00 (input/output) | $3.00 (input) / $7.00 (output) | $3.00 (input) / $8.00 (output) |
| DeepSeek R1 Distill Llama 70B | $0.40 | $2.00 | Not listed |
| DeepSeek V3 | $1.20 | $1.25 | $0.90 |
| Llama 3.1 70B Instruct | $0.40 | $0.90 | $0.90 |
| Llama 3.1 8B Instruct | $0.03 | $0.10 | $0.20 |
| Qwen 2.5 7B Vision Instruct | $0.20 | $0.30 | Not listed |
| Mistral Nemo 12B Instruct | $0.10 | Not listed | Not listed |
All prices are per 1 million tokens.
As shown above, Inference.net’s rates are extremely low across various models. This means you can handle billions of tokens at a fraction of the cost elsewhere. With no upfront commitments or subscriptions, such affordability lowers the barrier to experimenting or launching AI-driven products.
Model Testing: Faster Inference Speed
To evaluate the real-world performance of Inference.net, we conducted speed and latency tests using shared models from both Together AI and Inference.net. The results clearly demonstrate that Inference.net provides significantly faster inference calls:
- Generation Time: Inference.net took approximately 10.65 seconds per call, while Together AI required about 17.11 seconds.
- Time to First Token: Inference.net's latency was just 0.33 seconds compared to 0.73 seconds for Together AI.
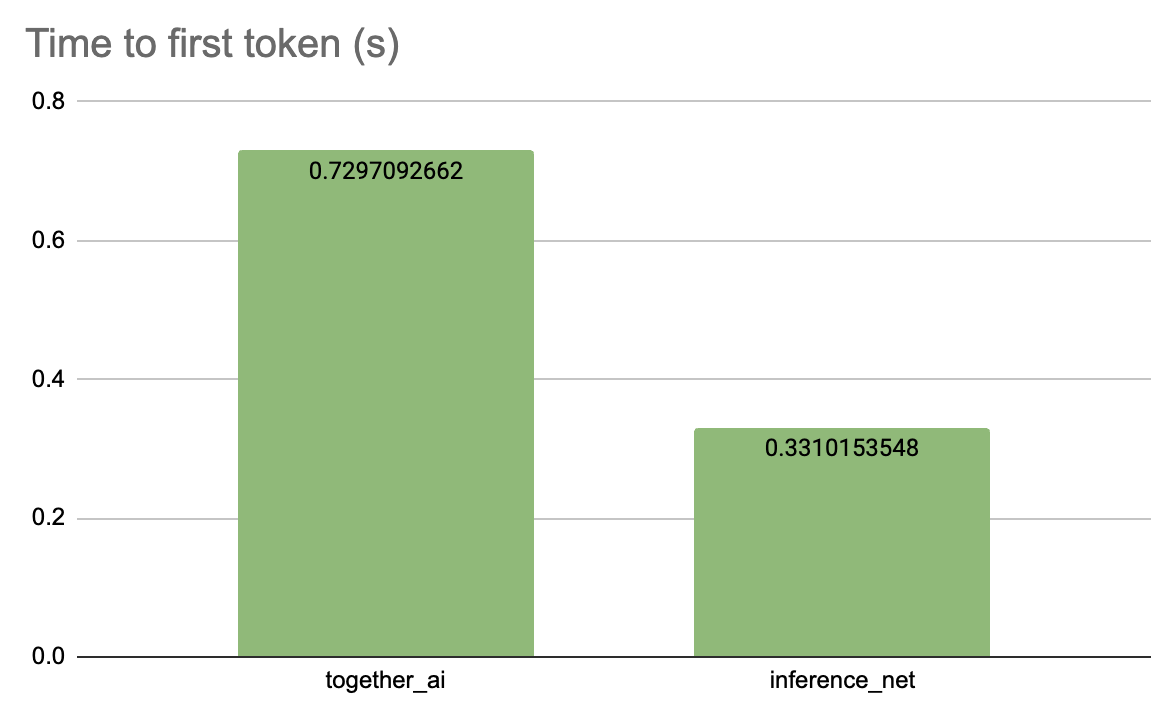
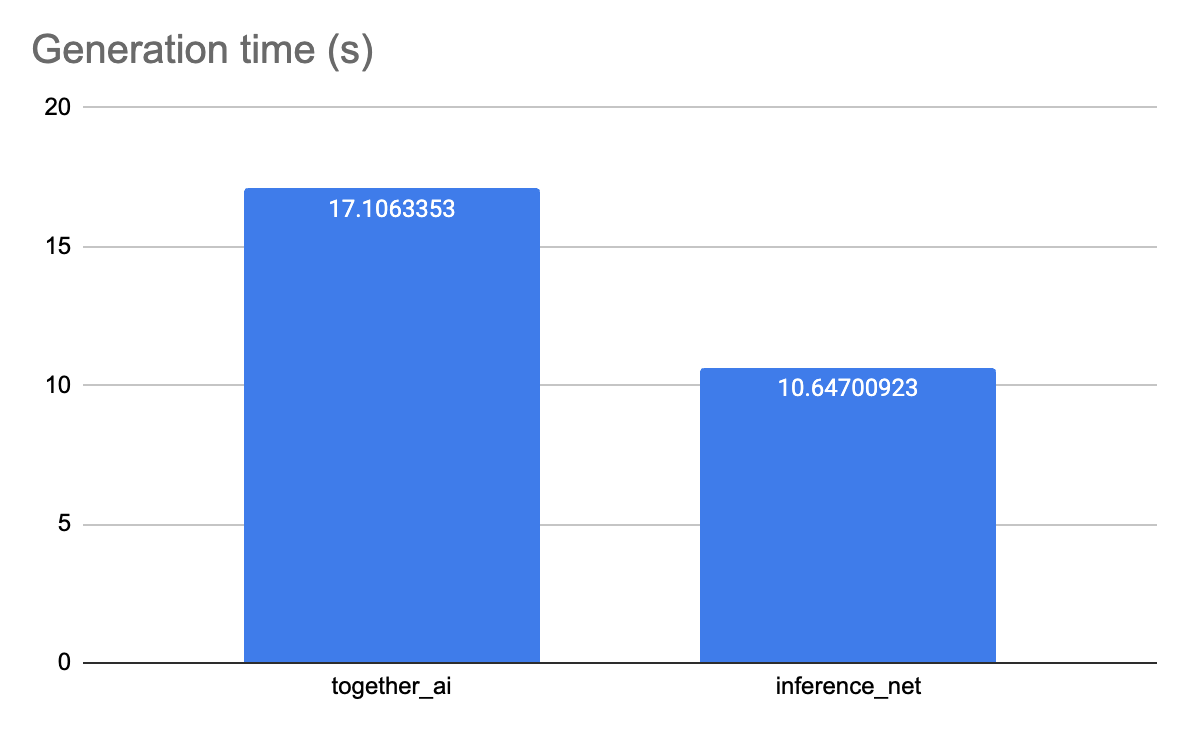
These metrics highlight Inference.net’s capability to deliver quicker responses and reduced waiting times, essential for applications demanding low latency and high responsiveness.
How to Use Inference.net
Using Inference.net is straightforward and flexible. You have two main options:
- Direct Integration: Add models directly from Inference.net to your application using its OpenAI-compatible API. Simply select your desired model, obtain an API key, and start making calls immediately.
- Using Keywords AI Gateway: Alternatively, you can utilize the Keywords AI gateway, which seamlessly supports calling models from Inference.net and over 300 other LLMs. Keywords AI automatically logs all LLM requests, responses, and relevant details, providing robust observability and management for your AI integrations.
Both methods ensure easy access and efficient integration of powerful open-source LLMs into your workflows.
Why Inference.net Stands Out
Inference.net combines performance, flexibility, and affordability, making it an ideal choice for:
- Developers & Startups: Quickly integrate open-source models using familiar APIs, and scale affordably as you grow.
- Enterprise Teams: Meet production demands with a globally distributed infrastructure and enterprise-grade reliability while controlling costs and avoiding vendor lock-in.
- Researchers: Access the latest models and run experiments at high speed, with transparent usage-based pricing and options to fine-tune models.


