Keywords AI
How to increase your LLM rate limits for free
As large language model (LLM) products continue proliferating, managing their rate limits becomes increasingly critical for developers. Rate limits for LLMs define the number of requests a user or client can make to the model within a specified timeframe. With the growing demand for these powerful tools, developers face the challenge of ensuring their applications can handle high traffic without running into rate limit constraints. Addressing this issue is essential to prevent customer-facing errors and maintain a seamless user experience. Understanding and enhancing your LLM rate limit is key to optimizing performance and reliability.
In this blog, we’ll delve into how you can enhance your LLM rate limit and avoid LLM downtime, ensuring optimal performance and reliability for your applications.
Rate Limits of Leading LLM Providers
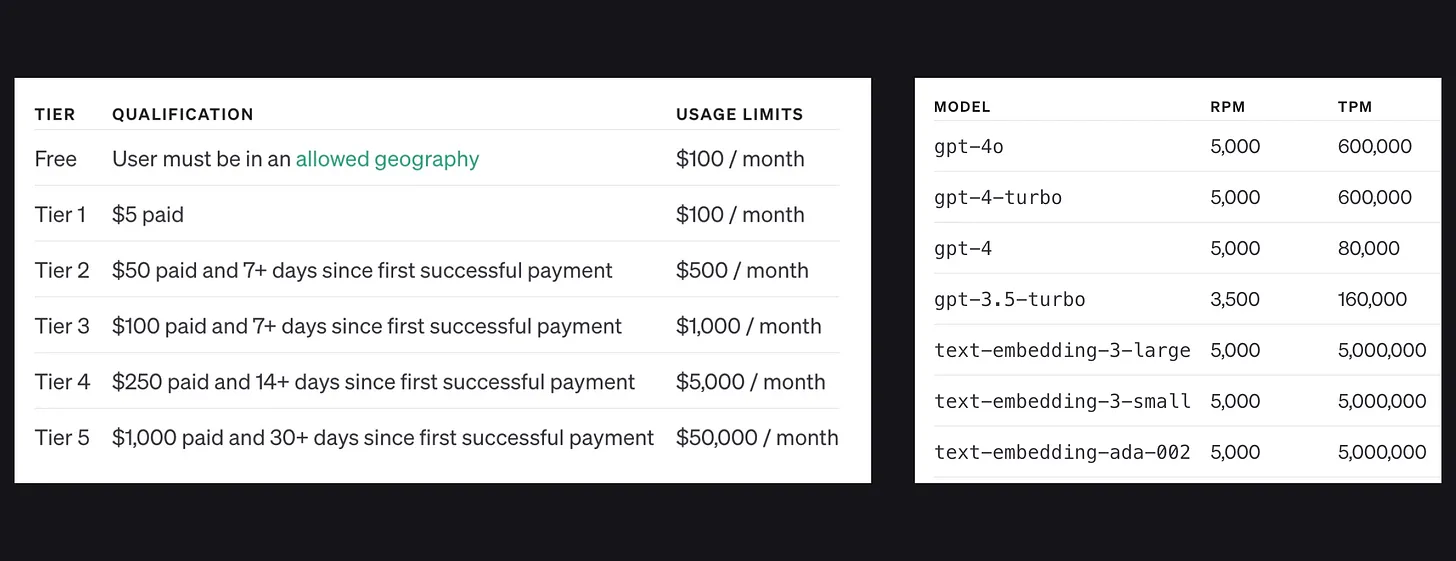
OpenAI
OpenAI offers 6 tiers for users, ranging from a free tier to tier 5, each with varying rate limits based on your spending. For instance, if your monthly expenditure is between $500 and $1,000, the rate limit for flagship models like gpt-4o will be 5,000 requests per minute (5,000 RPM).
Anthropic
Anthropic’s rate limits are similar to OpenAI's, with 1 free tier and 4 paid tiers (tiers 1 to 4). At a monthly spending of over $1,000, users can achieve a maximum rate limit of 4,000 RPM and a maximum usage cap of $5,000 per month.

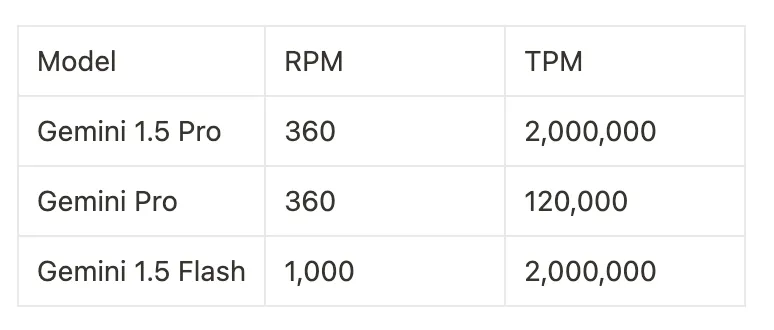
Gemini
Despite Gemini’s impressive performance for AI products, its rate limits are relatively low. The top model, Gemini 1.5 Pro, supports only 360 requests per minute (RPM), but its tokens per minute (TPM) is significantly higher than those of OpenAI and Anthropic.
Strategies to Enhance LLM Rate Limits Without Additional Costs
Load balancing between models
Load balancing between models involves distributing your LLM requests across multiple models proportionally. By utilizing different LLMs with similar performance levels, you can effectively manage and optimize your rate limits. This approach ensures that no single model is overwhelmed, thereby reducing the likelihood of hitting rate limits and maintaining smooth operations.
For instance, Keywords AI’s load balancing feature allows you to easily control your LLM rate limits by distributing requests among various models. You can use models like Anthropic Haiku, Gemini 1.5 Flash, and GPT-3.5-turbo simultaneously, specifying their weights to balance the load efficiently.
In the example below, 50% of your requests are directed to Claude 3 Haiku, while 25% go to GPT-3.5-turbo and Gemini 1.5 Flash each:

Load balancing between API keys
Sometimes, you may prefer not to distribute your API requests across different models and instead want a single LLM to handle all your requests. In such cases, load balancing between API keys from a single provider is the best solution.
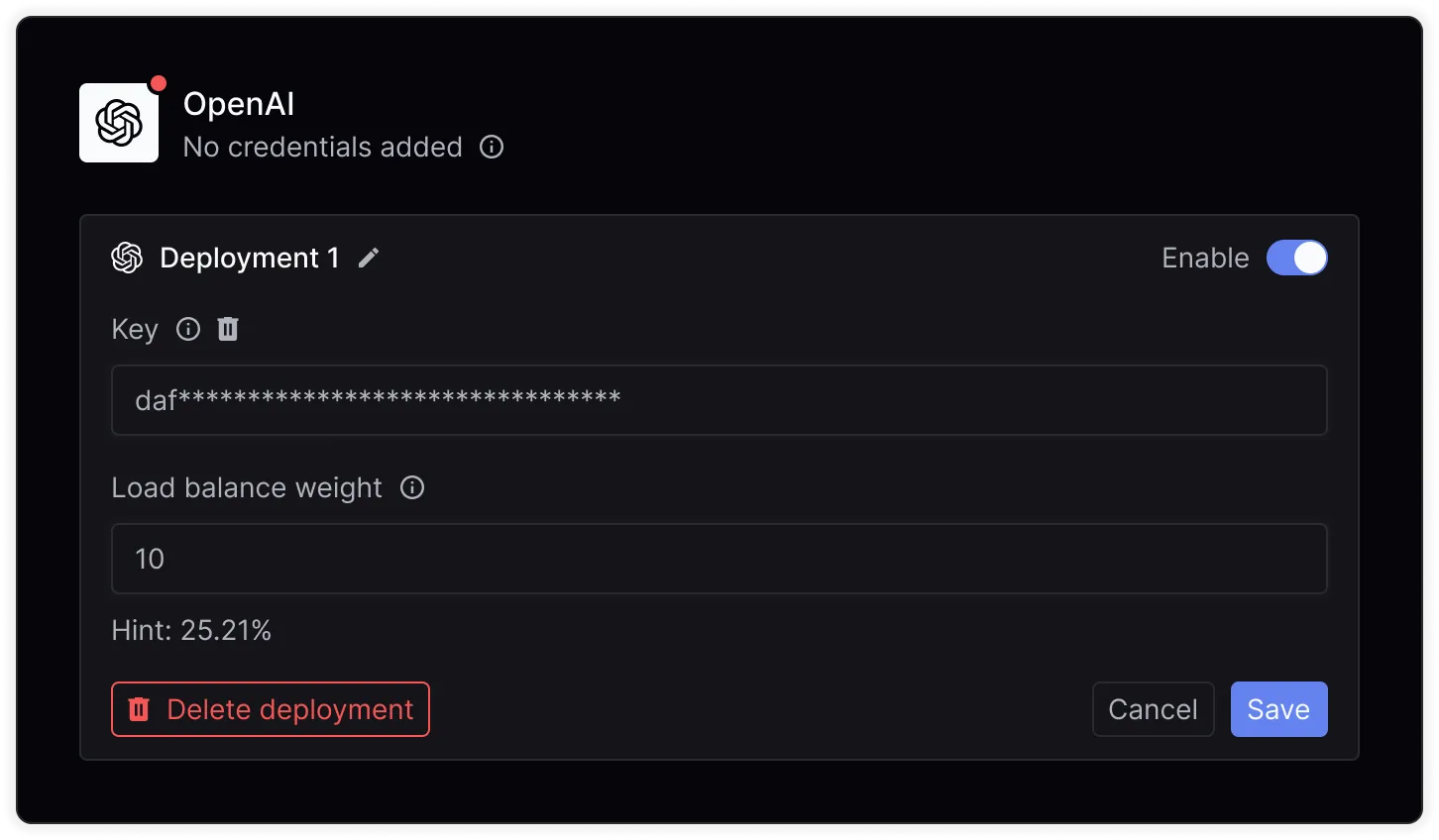
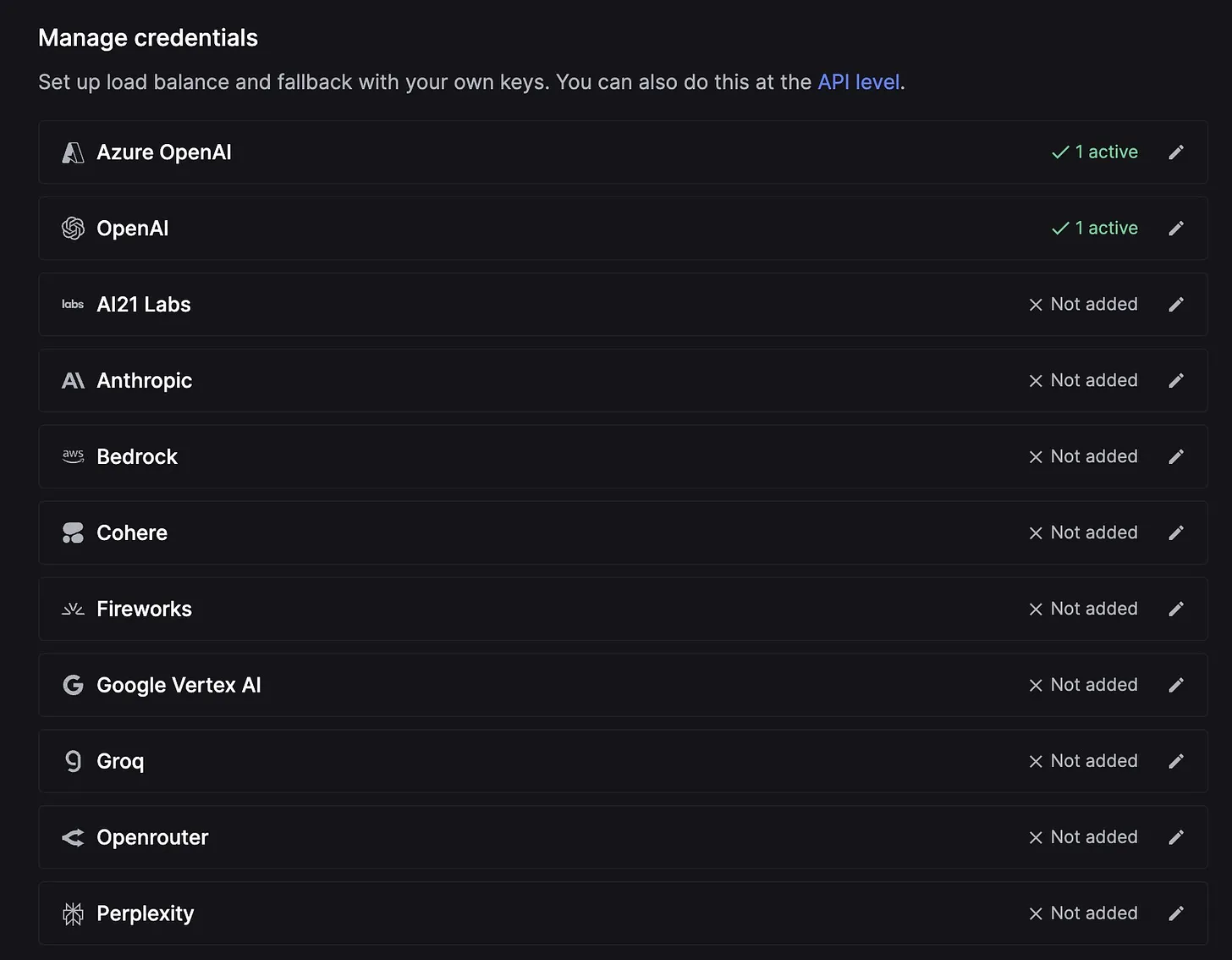
To achieve this, you need to create multiple accounts with a single provider and generate API keys for each account. Then, navigate to the Keywords AI Credential page to add your credentials and specify weights for each deployment.
You can also add load balancing for any other providers you use on the platform, ensuring optimal management of your rate limits across various credentials.
Additional Strategies to Enhance Your LLM Rate Limits
Besides the two primary methods, there are several other ways to enhance your LLM rate limits:
- Request Higher Rate Limits from Providers: If you have a substantial spending history with a provider, you can request them to manually increase your rate limits. This option is viable but typically requires significant expenditure for approval.
- Use OpenAI’s Batch API: For use cases that do not require synchronous processing, OpenAI’s asynchronous Batch API is an excellent option. It offers higher rate limits and is more cost-effective than synchronous processing. However, responses can take up to 24 hours, making it unsuitable for real-time applications.
- Build Your Own Load Balancing Solution: If data privacy is a concern, building your own load balancing solution might be the best route. While this approach ensures full control over your data, it requires significant effort and technical expertise. Leveraging third-party packages can help streamline this process, but it will still demand considerable time and resources.


