Keywords AI
A YC startup's first project - an LLM router (with code)
Last September, Andy came across a paper that introduced the concept of FrugalGPT. This paper presented a method for reducing the cost of using Large Language Models (LLMs) while maintaining comparable performance by leveraging various smaller models.
Inspired by FrugalGPT, we quickly turned theory into practice. Raymond developed a Minimum Viable Product (MVP) for an LLM router in just one week, followed by a front-end implementation the next week. Remarkably, we secured our first customer by week three.
This blog post will guide you through our journey of building the LLM router MVP and provide insights on how you can create your own.
What is FrugalGPT?
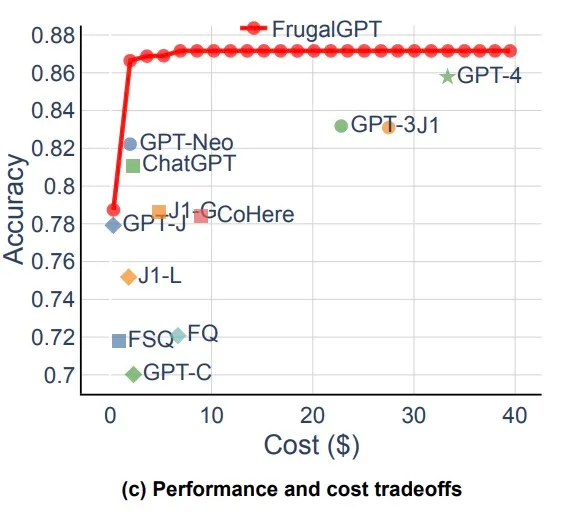
FrugalGPT is a framework designed to reduce the costs of using Large Language Models (LLMs) while maintaining or improving performance. It employs three strategies:
- Prompt Adaptation: Reducing the length of prompts to save costs.
- LLM Approximation: Using cheaper models or caching responses to approximate expensive LLMs.
- LLM Cascade: Sequentially querying different LLMs, starting with cheaper ones and only using expensive models if necessary.
FrugalGPT can significantly cut costs (up to 98%) and even enhance accuracy by up to 4% compared to using a single LLM like GPT-4.
Initial concept of the LLM router
After thoroughly reviewing the FrugalGPT paper, Andy recognized its potential to significantly reduce costs for AI startups and developers. This was particularly relevant to us, as our one-stop job search copilot consumed substantial daily resources on OpenAI.
Our investigation led us to focus on LLM approximation, which we found to be the most practical and efficient strategy for our use case. To rapidly gather user feedback, we created a simplified LLM router integrating only GPT-3.5 Turbo and GPT-4.
At the time, the cost difference between these models was substantial:
- GPT-4: $30 (input) and $60 (output) per million tokens
- GPT-3.5 Turbo: $0.5 (input) and $1.5 (output) per million tokens
This stark contrast highlighted the importance of efficient model selection. After all, you wouldn't want your AI application to use the expensive GPT-4 for simple responses like "Hello"!
Developing the MVP: Architecture and Classification System
Our LLM router concept utilizes an embedding model (text-embedding-3-small from OpenAI) to classify input, generate a vector score, and select the most suitable LLM based on that score. To enhance the router's model selection capability, we first established our evaluation and model ranking framework.
Model Ranking System:
We defined models and their characteristics in our backend:
python1gpt_4 = ModelParam( 2 model_name="gpt-4", 3 speed=48, 4 max_context_window=8192, 5 model_size=170, 6 mmlu_score=86.4, 7 mt_bench_score=8.96, 8 big_bench_score=83, 9 input_cost=30, 10 output_cost=60, 11 rate_limit=10000, 12 function_call=1 13) 14 15gpt_3_5_turbo = ModelParam( 16 model_name="gpt-3.5-turbo", 17 speed=150, 18 max_context_window=4096, 19 model_size=20, 20 mmlu_score=70, 21 mt_bench_score=7.94, 22 big_bench_score=71.6, 23 input_cost=0.5, 24 output_cost=0.1, 25 function_call=1 26) 27 28difficulty_details = { 29 "1": "This query is just as a greeting or the most basic human interaction.", 30 "2": "This is a simple question that can be answered with a single sentence.", 31 "3": "This question requires a few sentences to answer, probably some logic or reasoning, basic coding question, or short JSON parsing.", 32 "4": "This question requires a paragraph to answer, requires a fair amount of logic and reasoning, coding algorithm, or long JSON parsing.", 33 "5": "This question requires a long answer, intricated logic or reasoning, complicated coding questions, or complicated nested JSON parsing." 34} 35 36category_details = { 37 "Writing": "Engaging in narrative and creative text generation.", 38 "Questions": "Responding to inquiries across various topics.", 39 "Math": "Performing calculations and interpreting data.", 40 "Roleplay": "Engaging in simulated dialogues and scenarios.", 41 "Analysis": "Performing sentiment analysis, summarization, and entity recognition.", 42 "Creativity": "Generating ideas and concepts in arts and design.", 43 "Coding": "This task requires coding assistants and code generation.", 44 "Education": "Developing learning materials and providing explanations.", 45 "Research": "Conducting online research and compiling information.", 46 "Translation": "Translating text across multiple languages." 47} 48 49format_details = { 50 "PlainText": "Standard unformatted text responses.", 51 "StructuredData": "JSON, XML, and YAML output for structured data formats.", 52 "CodeScript": "Generation of source code and executable scripts.", 53 "ListOutput": "Bullet points and numbered list formats.", 54 "InteractiveText": "Q&A style and other interactive text elements.", 55 "Customized": "Custom instructions and unique output formats." 56} 57 58expertise_details = { 59 "STEM": "Covering science, technology, engineering, mathematics topics.", 60 "Humanities": "Specializing in literature, history, philosophy, arts.", 61 "Business": "Expertise in economics, management, marketing.", 62 "Health": "Providing healthcare and medical knowledge.", 63 "Legal": "Insights into law, politics, and governance.", 64 "Education": "Specializing in teaching and learning techniques.", 65 "Environment": "Focus on ecology, geography, and environmental science.", 66 "Tech": "Information technology, computer science, AI specialization.", 67 "Arts": "Covering music, visual arts, and entertainment.", 68 "Social": "Understanding of sociology, psychology, anthropology." 69}
Router Implementation
The core routing logic uses embedding similarity to determine query complexity and route to the appropriate model:
python1def route_query(query: str, embedding_model: str = "text-embedding-3-small"): 2 """ 3 Route a query to the most appropriate LLM based on complexity analysis. 4 """ 5 # Get query embedding 6 embedding = get_embedding(query, embedding_model) 7 8 # Calculate complexity score 9 complexity_score = calculate_complexity(embedding, query) 10 11 # Route based on complexity 12 if complexity_score < 0.3: 13 return gpt_3_5_turbo 14 else: 15 return gpt_4 16 17def calculate_complexity(embedding, query): 18 """ 19 Calculate query complexity based on various factors. 20 """ 21 # Length factor 22 length_factor = min(len(query.split()) / 100, 1.0) 23 24 # Keyword-based complexity detection 25 complex_keywords = ['algorithm', 'implement', 'analyze', 'complex', 'detailed'] 26 keyword_factor = sum(1 for word in complex_keywords if word in query.lower()) / len(complex_keywords) 27 28 # Combine factors (this is simplified - in practice you'd use ML models) 29 complexity = (length_factor + keyword_factor) / 2 30 31 return complexity
This approach allowed us to automatically route simple queries to the cost-effective GPT-3.5 Turbo while reserving GPT-4 for complex tasks that truly required its advanced capabilities.
For more detailed implementation and the complete codebase, check out our full article on Medium.


