Keywords AI
Week of Open-Source models: Mistral Large 2 vs. Llama 3.1 405B
Intro
This week has been bustling with activity in the open-source AI community. Meta unveiled its new flagship model, Llama 3.1 405B, along with its smaller counterparts, the 70B and 8B models. Not to be outdone, Mistral quickly followed suit by releasing its latest top-tier model, the Mistral Large 2, boasting an impressive 123B parameters.
In this blog, we'll dive deep into a comparison of these two powerhouse models and offer recommendations to help you choose the one that best suits your needs.
Basic Comparison
Both the Llama 3.1 405B and Mistral Large 2 models are open-source, making them accessible for hosting on your desktop or through an AI gateway. For our analysis, we utilized Keywords AI, a platform that allows seamless integration with over 200 LLMs using a unified format.
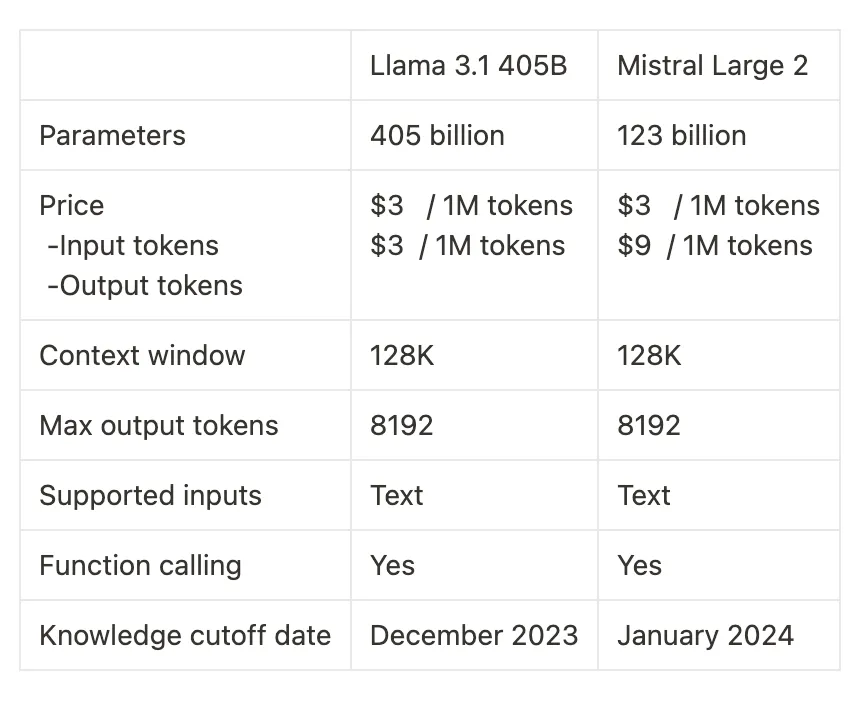
While both models offer substantial parameter counts, context windows, and max output tokens, the Llama 3.1 405B stands out with its significantly higher parameter count. However, the Mistral Large 2 has a later knowledge cutoff date, potentially offering more up-to-date information. Pricing structures are similar for input tokens but differ for output tokens, with Mistral Large 2 being more expensive.
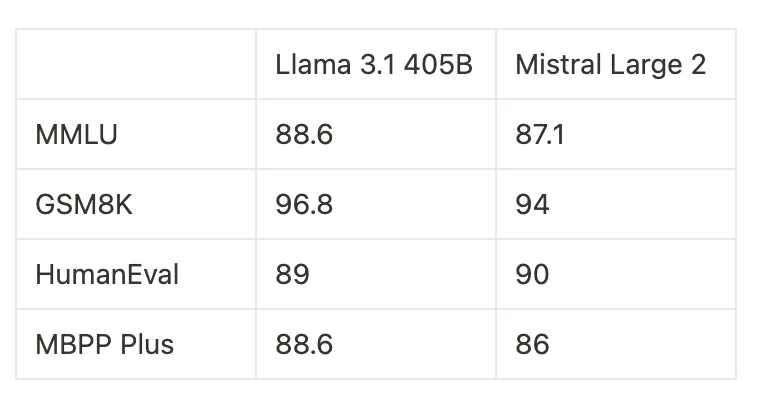
Llama 3.1 405B generally leads in MMLU and GSM8K, indicating strong performance in multi-task language understanding and grade school math problems. However, Mistral Large 2 excels in the HumanEval benchmark, demonstrating superior coding capabilities. The MBPP Plus scores show a closer competition, with Llama 3.1 405B slightly ahead.
Speed comparison
Latency
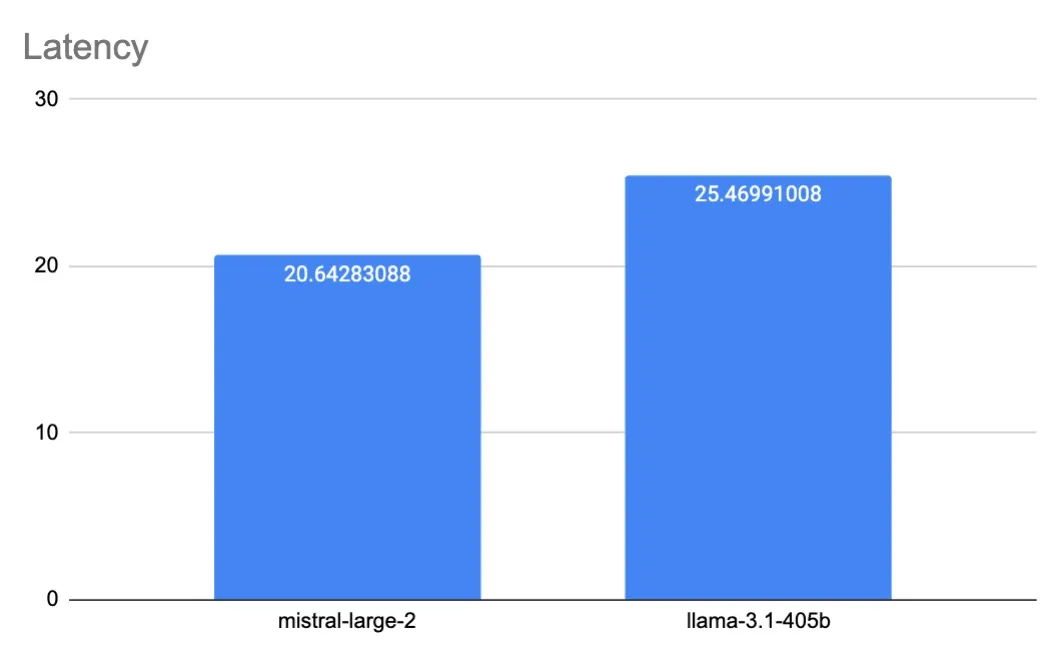
In terms of latency, Mistral Large 2 and Llama 3.1 405B perform at comparable levels. Our tests, consisting of hundreds of requests for each model, revealed that Mistral Large 2 has an average latency of 20.642 seconds, while Llama 3.1 405B averages at 25.47 seconds. Despite these differences, the overall generation times for both models are quite similar, indicating no significant disparity in performance.
TTFT (Time to first token)
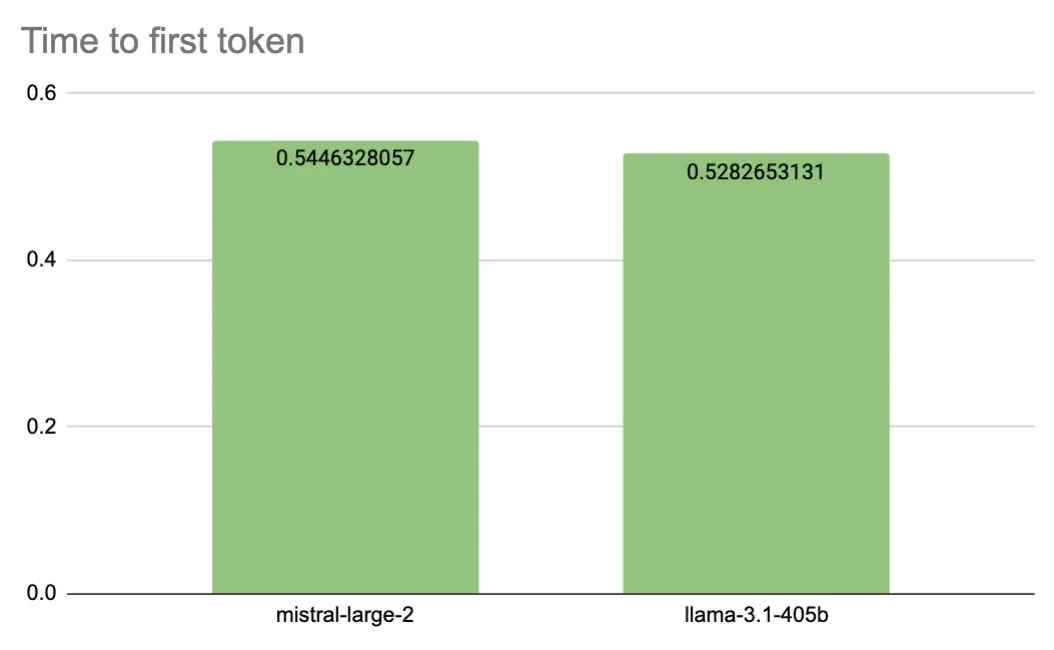
The Time to First Token (TTFT) for Mistral Large 2 and Llama 3.1 405B is remarkably similar. Mistral Large 2 averages a TTFT of 0.5446 seconds, while Llama 3.1 405B comes in at 0.5282 seconds. Both models have TTFTs of around 0.5 seconds, which, while slower than GPT-4o and Claude 3.5 Sonnet, still represents a good performance level.
Throughput (Tokens per second)
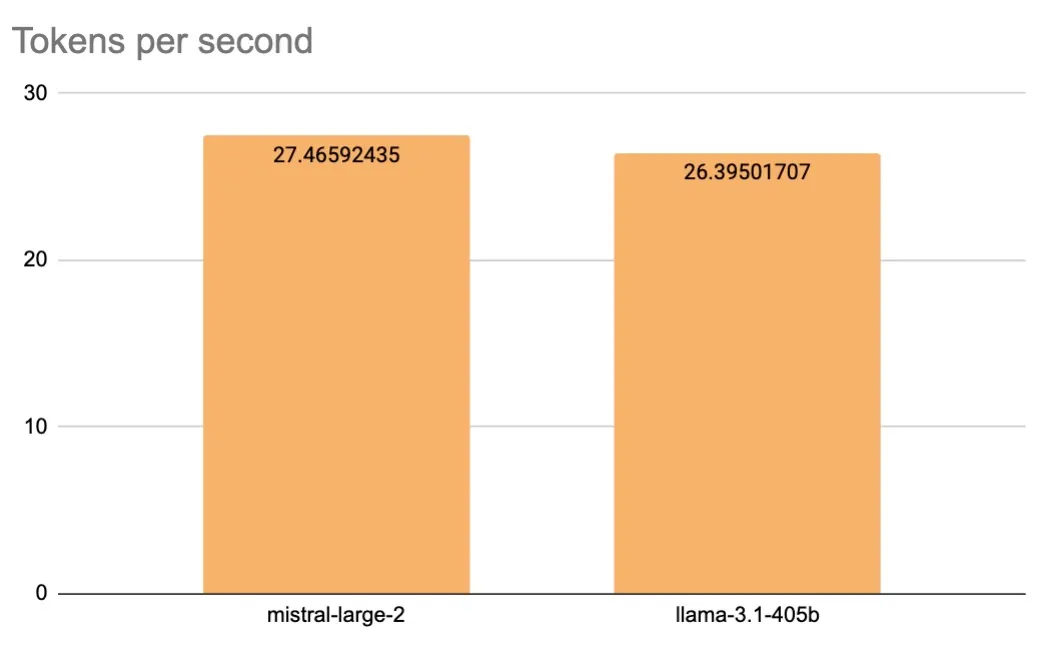
The throughput for Mistral Large 2 and Llama 3.1 405B is relatively modest, with Mistral Large 2 achieving 27.465 tokens per second and Llama 3.1 405B reaching 26.395 tokens per second. This throughput, around 25 tokens per second, is significantly slower than that of GPT-4o and Claude 3.5 Sonnet. However, it is comparable to models like Claude 3 Opus and GPT-4.
In terms of speed, both Mistral Large 2 and Llama 3.1 405B deliver similar performance levels across various metrics. Their latency is comparable, with Mistral Large 2 slightly ahead at 20.642 seconds versus Llama 3.1 405B's 25.47 seconds. The Time to First Token (TTFT) for both models hovers around 0.5 seconds, demonstrating their efficiency despite being marginally slower than some of the latest offerings like GPT-4o and Claude 3.5 Sonnet. When it comes to throughput, both models perform at around 25 tokens per second, aligning them more closely with models like Claude 3 Opus and GPT-4. Overall, while neither model leads the pack in speed, they maintain competitive performance levels that are suitable for many applications.
Performance comparison
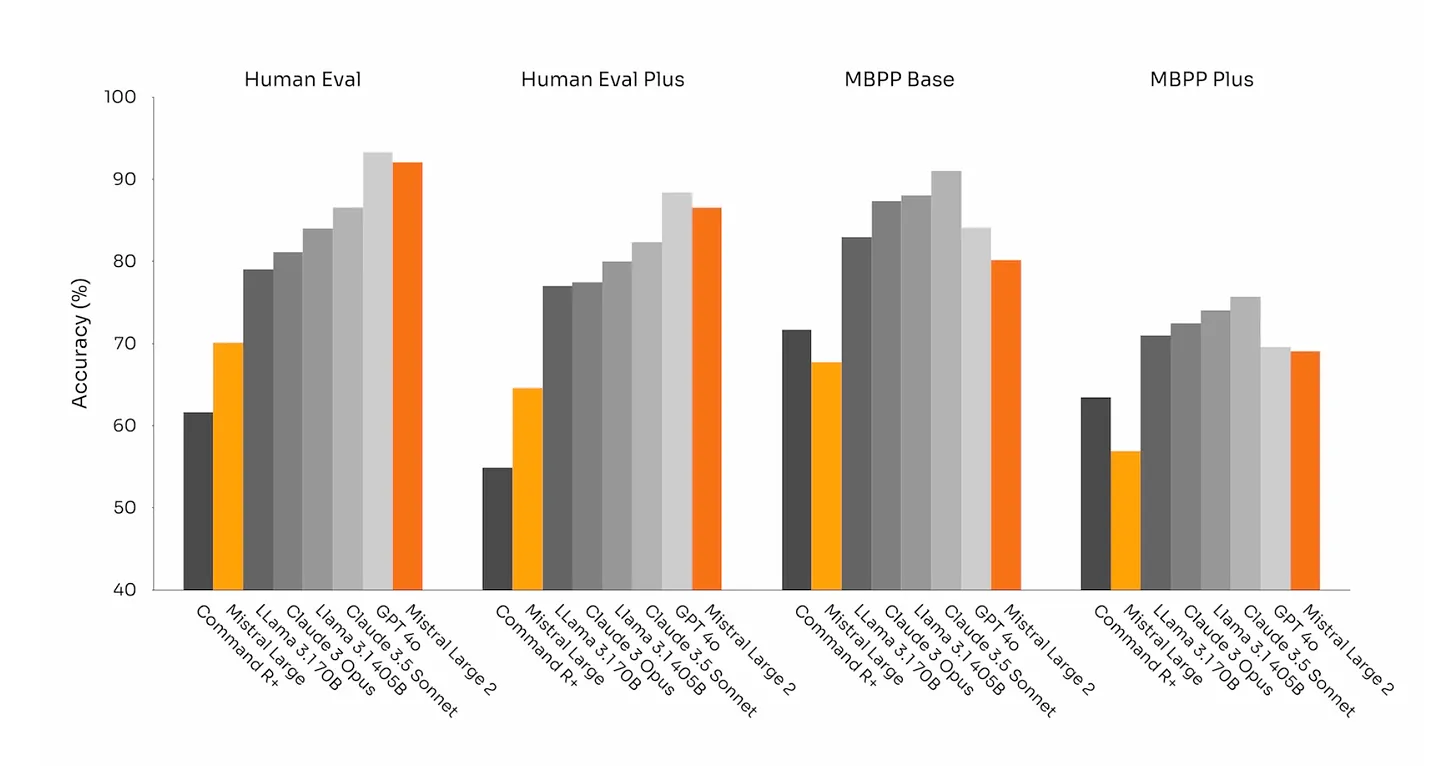
We conducted evaluation tests on the Keywords AI platform. The evaluation comprised three parts:
- Coding Task: Both models were tested on debugging the frontend development of Keywords AI. Their understanding of coding was comparable, but Mistral Large 2 exhibited a slightly smarter problem-solving approach in certain instances compared to Llama 3.1 405B.
- Document Processing: Large documents (around 100 pages) were provided to the models for information extraction. Both models demonstrated strong capabilities in this area. However, their slower processing speeds make them less ideal for handling large documents efficiently.
- Logical Reasoning: Llama 3.1 405B outperformed Mistral Large 2 in logical reasoning tasks. Mistral Large 2 made some incorrect explanations and provided wrong answers, whereas Llama 3.1 405B consistently delivered accurate and reliable responses.
Conclusion
In conclusion, our evaluations reveal distinct strengths and weaknesses for both Mistral Large 2 and Llama 3.1 405B. Mistral Large 2 demonstrated smarter problem-solving abilities in coding tasks, while Llama 3.1 405B excelled in logical reasoning. Both models performed well in document processing but are hampered by slower processing speeds, making them less suitable for extensive document handling. Overall, these tests highlight that each model has unique advantages, and the best choice depends on the specific requirements of your use case.
Model recommendations:
Llama 3.1 405B:
- Best For: Logical reasoning tasks, complex problem-solving, and applications requiring high parameter counts for nuanced understanding and detailed responses.
- Not suitable for: Tasks requiring fast processing speeds, such as real-time document processing or applications where throughput is critical. Additionally, due to its large parameter size, hosting the 405B model can be prohibitively expensive for individual users.
Mistral Large 2:
- Best For: Coding tasks, especially those requiring intelligent problem-solving and debugging. It also performs well in scenarios where slightly faster latency is beneficial.
- Not suitable for: Tasks requiring precise logical reasoning and accuracy, as well as applications demanding high throughput for large-scale document processing.
Where to try these open-source models?
Self-hosting open-source models has its own strengths, offering complete control and customization. However, it can be inconvenient for developers who want a simpler and more streamlined way to experiment with these models.
Consider using Keywords AI, a platform that allows you to access and test over 200 LLMs using a consistent format. With Keywords AI, you can try all the trending models with a simple API call or use the model playground to test them instantly.


