Keywords AI
LLM Benchmarking: A complete guide to evaluating LLM in 2024
New LLMs are released almost weekly. These models, whether open-sourced or flagship, each have unique strengths. Some excel in generating low-cost conversational chatbots, while others are adept at coding or producing high-quality written content.
In this blog, we will delve into using benchmarks to evaluate LLMs. You'll learn how to compare the performance of models across different benchmarks, enabling you to select the most suitable LLM for your specific AI applications.
Before we dive into the benchmarks, check the LLM Leaderboard if you need the best overall model, regardless of cost or speed. It highlights top-performing models, helping you quickly find the most advanced options.
At the end of this blog, I'll demonstrate how to utilize all mainstream LLMs through a single platform or API call.
- Mathematical Benchmarks
- General Knowledge & Question Answering Benchmarks
- Coding Benchmarks
- Logical Reasoning Benchmarks
Mathematical Benchmarks
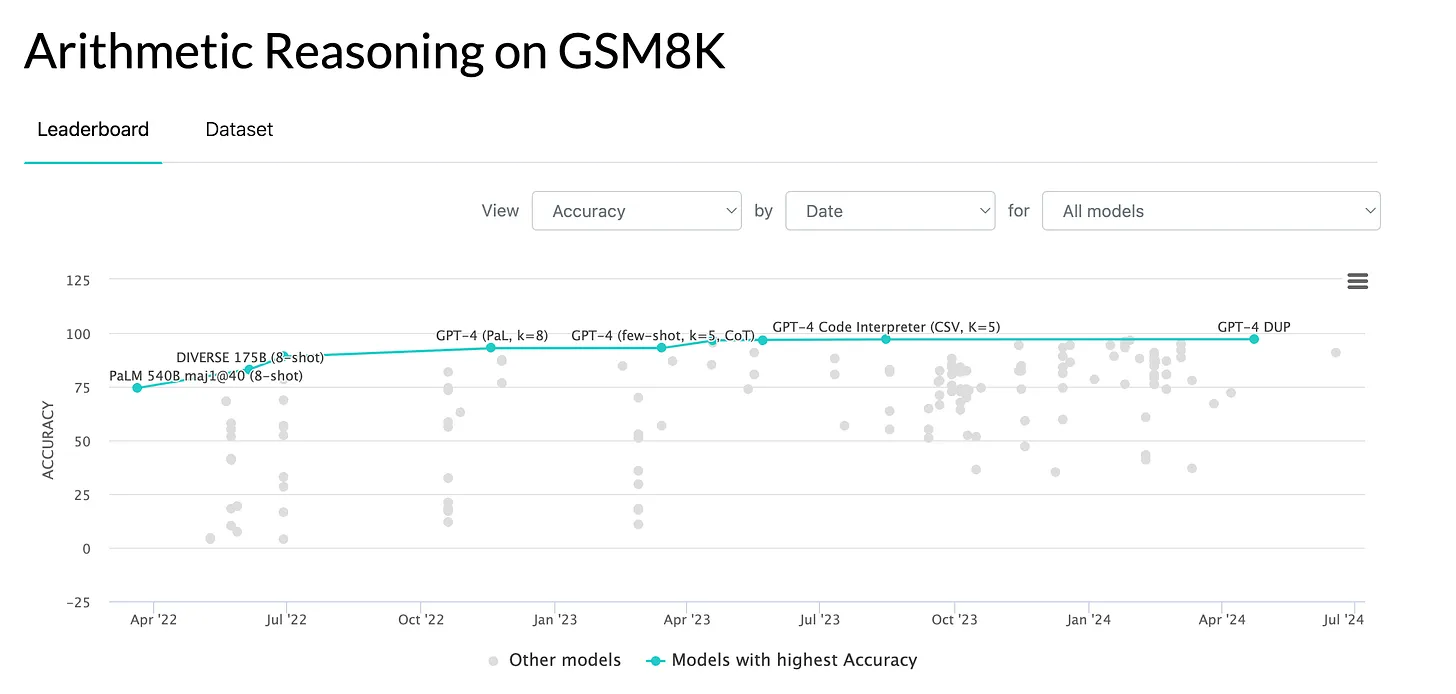
GSM-8K tests a model's ability to solve grade-school level math problems, focusing on numerical reasoning and understanding of elementary concepts. The dataset includes 8,500 math word problems that require 2 to 8 steps to solve, using basic arithmetic, algebra, and geometry. The final score is the percentage of correctly answered questions.
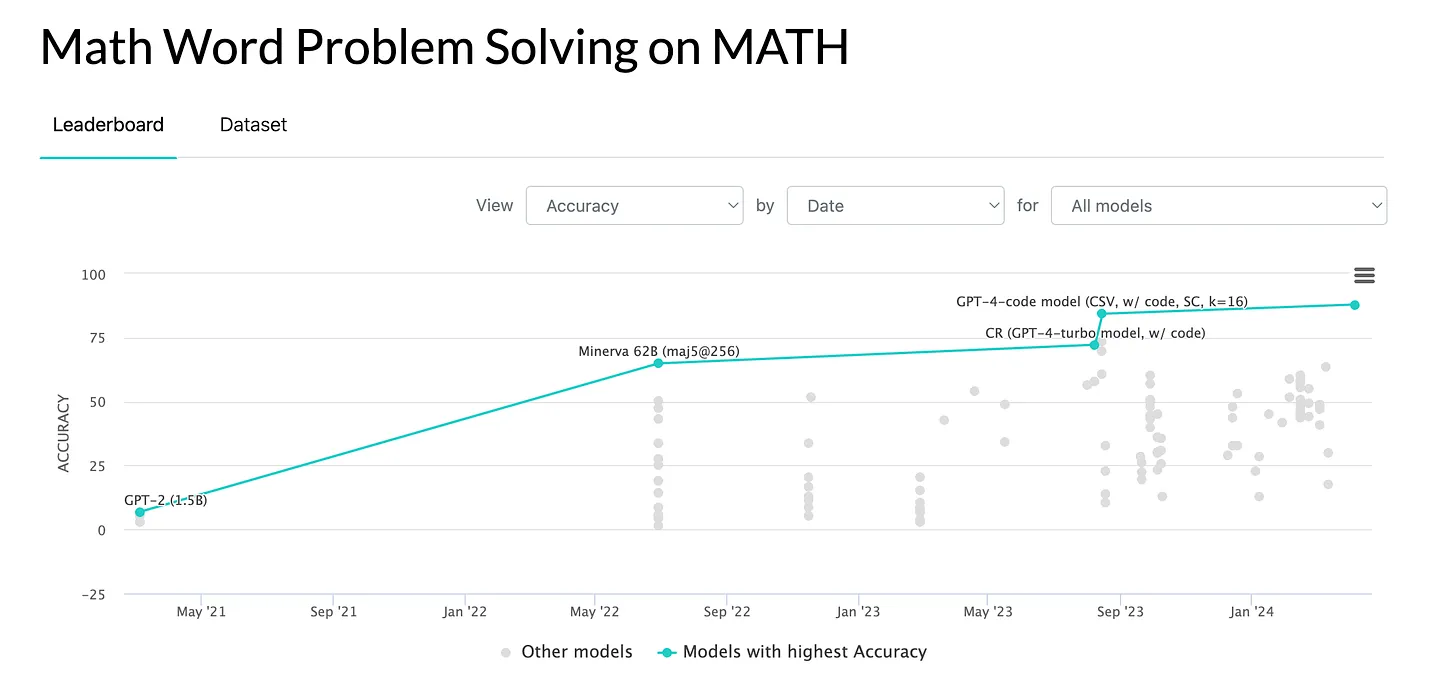
MATH is a benchmark with 12,500 challenging competition-level math problems, each accompanied by a detailed step-by-step solution. It assesses a model's ability to solve advanced math problems across five difficulty levels and seven sub-disciplines, including algebra, calculus, and statistics. The benchmark emphasizes the importance of detailed answer derivations and explanations.
General Knowledge & Question Answering Benchmarks
MMLU: Better Benchmarking for LLM Language Understanding
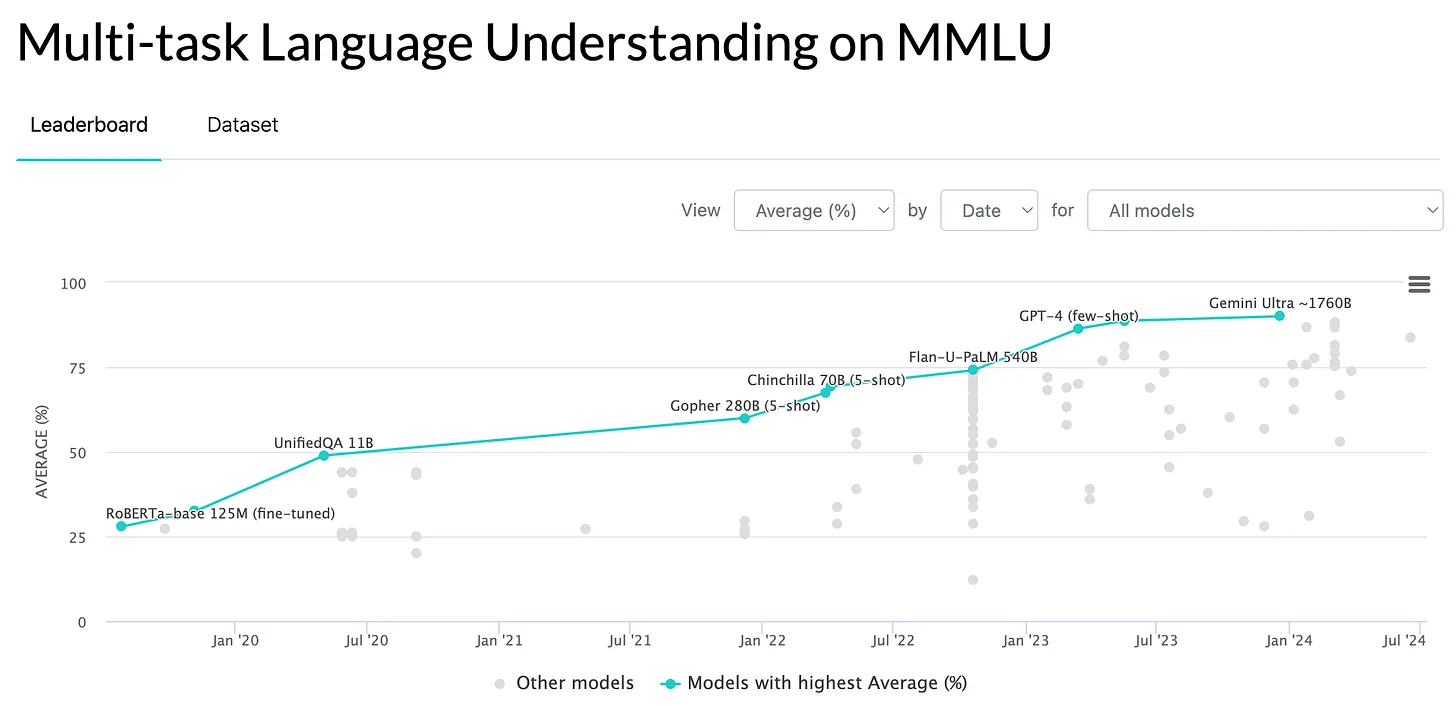
MMLU is a comprehensive benchmark designed to evaluate an LLM’s natural language understanding (NLU) and problem-solving abilities across diverse subjects. It comprises 15,908 questions divided into 57 tasks, covering STEM, humanities, social sciences, and other topics from elementary to professional levels. This benchmark assesses a model's ability to integrate and apply knowledge nuancedly rather than just factual recall.
Limitations of MMLU
MMLU has some limitations, including missing context in questions, ambiguous or incorrect answers, and errors in the dataset. Additionally, there is limited information on how the corpus was constructed, underscoring the need for more reliable benchmarking standards.
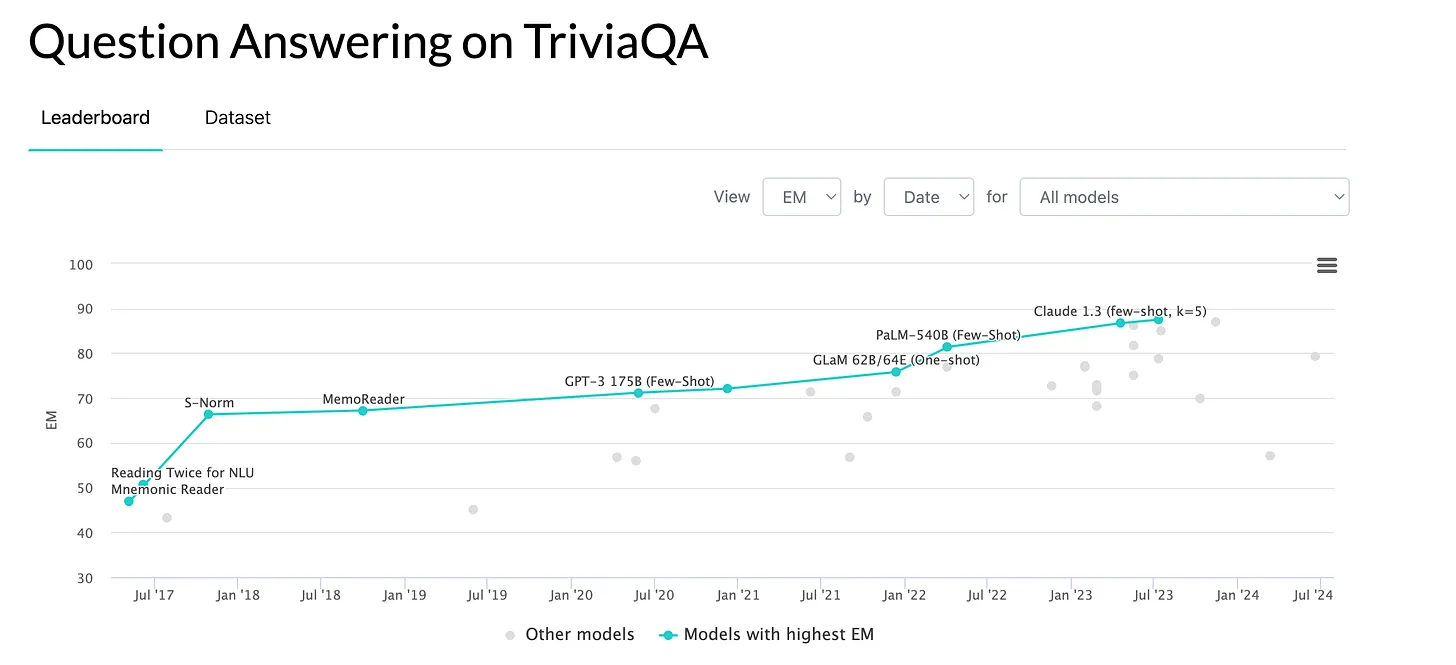
TriviaQA measures a language model's ability to generate truthful answers. It includes questions that humans often answer incorrectly due to false beliefs. Models must avoid replicating these errors. Larger models can be less truthful due to ingesting more false information. The challenge is to use provided documents to find and verify correct answers to trivia questions across various topics.
Coding Benchmarks
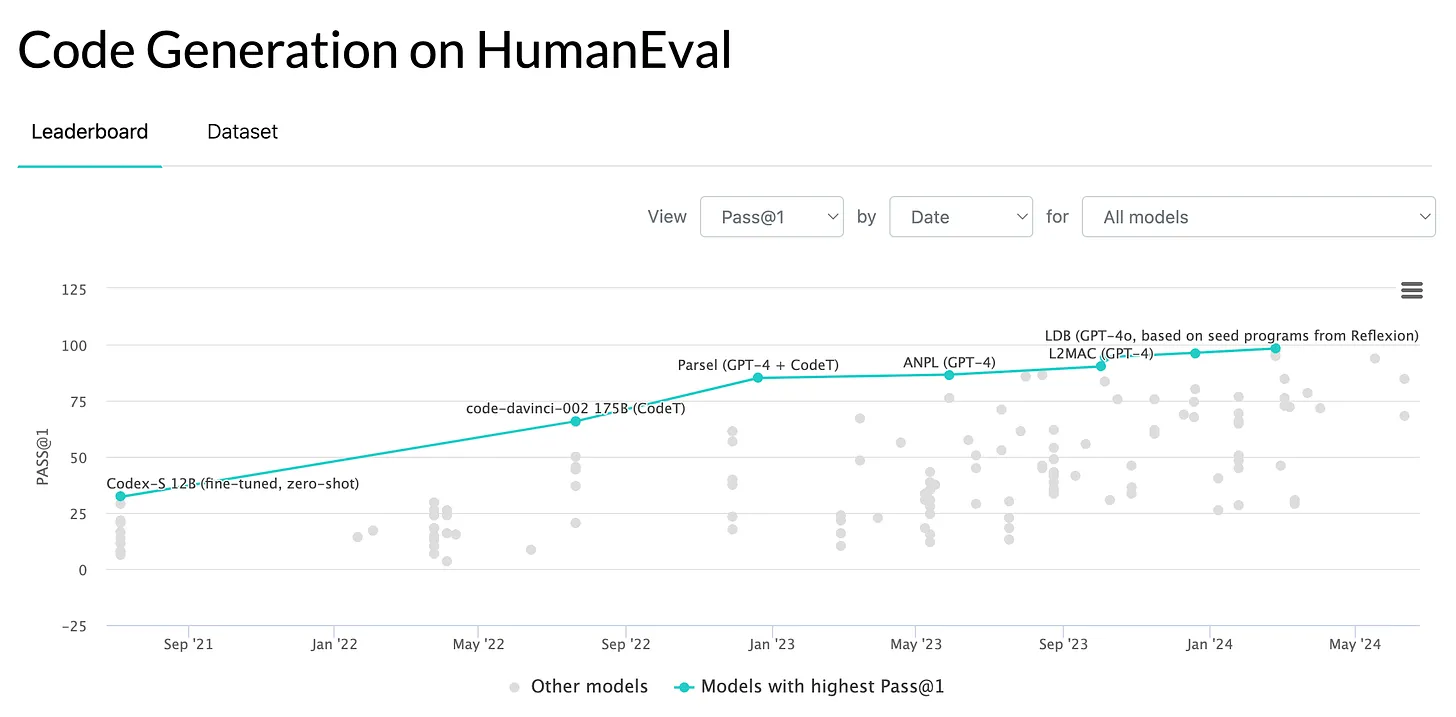
HumanEval, created by OpenAI, evaluates LLMs' ability to generate functional and correct Python code. It includes 164 hand-crafted programming challenges with unit tests and uses the pass@k metric to assess code correctness. This benchmark is crucial for measuring LLM performance in code generation tasks.
Limitations of HumanEval
Despite its significance, HumanEval has limitations. It mainly focuses on algorithmic problems, missing the complexity of real-world tasks. It doesn't test for writing tests, code explanation, or docstring generation; its unit tests can be weak. Additionally, biases and potential data exposure during training can overestimate model performance.
MBPP (Mostly Basic Python Programming)
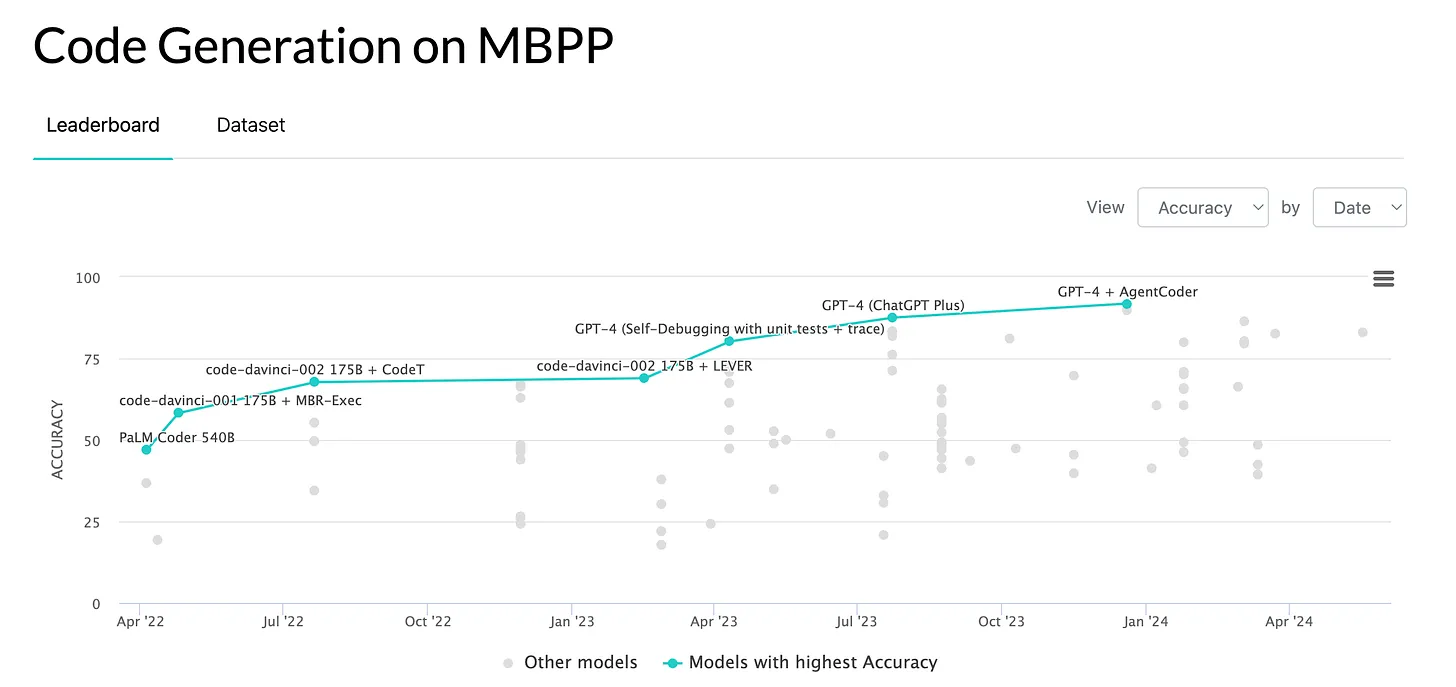
The Mostly Basic Programming Problems (MBPP) benchmark evaluates LLMs' ability to generate short Python programs from natural language descriptions. The dataset includes 974 entry-level programming tasks, each with a task description, code solution, and three automated test cases for functional correctness. MBPP covers more problems than HumanEval and consistently includes three input/output examples formatted as assert statements. This makes it a valuable tool for assessing both the correctness and efficiency of code generated by LLMs.
Logical Reasoning Benchmarks
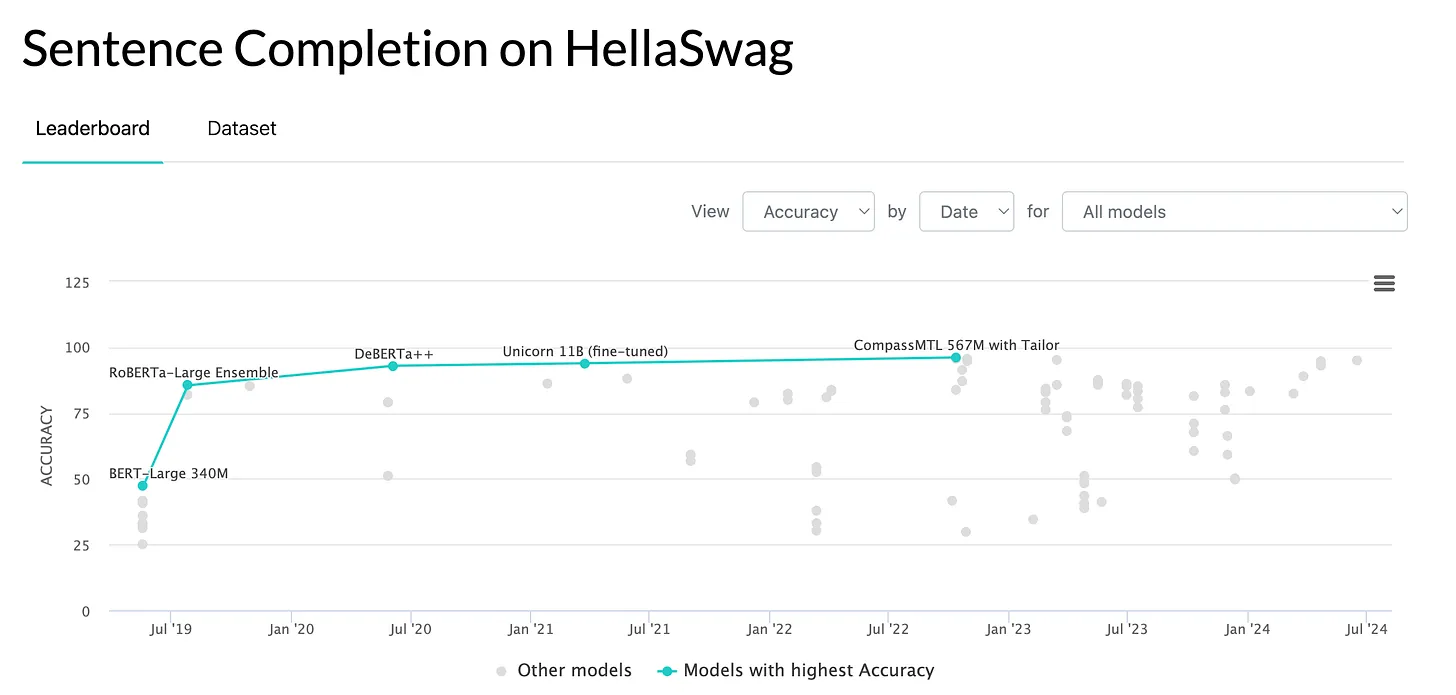
HellaSwag tests LLMs' commonsense reasoning through sentence completion tasks. Each question includes a video caption segment and four possible endings, with only one correct. Designed to challenge models, the scenarios are easy for humans but difficult for LLMs. Created using adversarial filtering, HellaSwag ensures complex and deceptive wrong answers to test models' everyday knowledge understanding.
Limitations of HellaSwag
HellaSwag struggles with nuanced contextual ambiguity, which can affect the accuracy of its results. Moreover, it focuses on general knowledge and does not adequately test commonsense reasoning in specialized domains.
The AI2 Reasoning Challenge (ARC) is a QA benchmark designed to test LLMs' knowledge and reasoning skills using 7787 multiple-choice science questions for grades 3 to 9. Divided into Easy and Challenge sets, these questions cover various types of knowledge, including factual, spatial, experimental, and algebraic.
Unlike benchmarks like SQuAD, ARC requires models to use distributed evidence and reasoning rather than merely extracting answers from text. This makes ARC a more comprehensive and difficult benchmark for evaluating language models. However, it only has scientific questions.
Where to Evaluate and Integrate Best-in-Class LLMs?
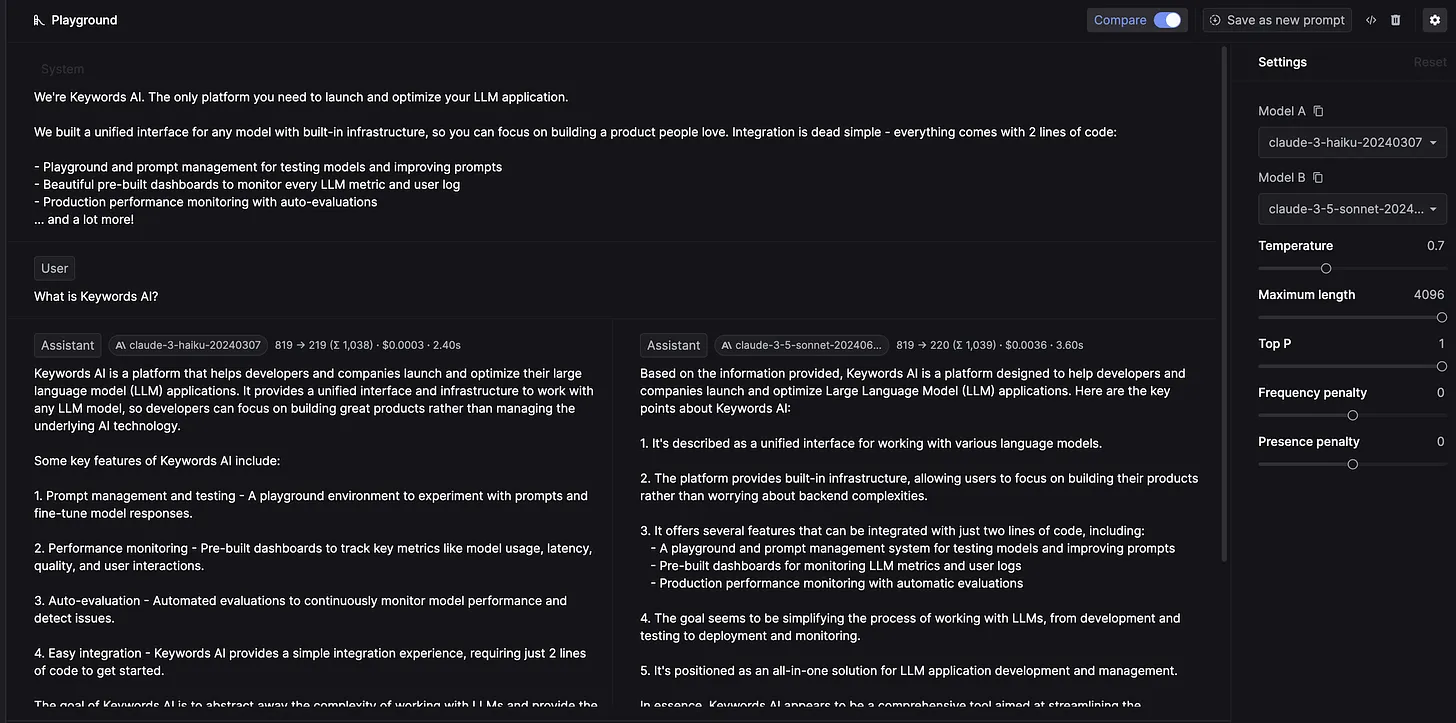
After selecting your desired LLMs based on specific benchmarks, testing them to ensure they meet your requirements is important, as benchmarks can have biases or be incomplete. Visit the Keywords AI LLM playground to compare different models' performance.
Once you manually evaluate the models, you can integrate them into your codebase using the Keywords AI OpenAI-compatible API.


