Keywords AI
Let’s think step by step: Chain of Thought prompting in LLMs
Introduction
LLMs are impressive feats of pattern recognition, able to sift through mountains of data and find connections invisible to the human eye. Yet, even with this prodigious ability, they sometimes stumble when faced with complex reasoning. They might offer a correct answer, but it's more akin to a lucky guess than genuine understanding. Chain-of-Thought prompting (CoT) offers a compelling solution to this intriguing paradox.
By providing the LLM with a "chain" of reasoning—a series of logical stepping stones composed of intermediate steps, justifications, and supporting evidence—we guide it through the problem-solving process. It's like giving the LLM a cognitive map, enabling it to navigate the intricate pathways of logic and arrive at an answer not through chance, but through genuine comprehension.
Explaining the concept
A 2022 Google Research paper, "Chain of Thought Prompting Elicits Reasoning in Large Language Models", introduced the concept of Chain-of-Thought (CoT) prompting. The researchers demonstrated that guiding large language models through intermediate reasoning steps, expressed in natural language, significantly boosted their performance on complex tasks.
These tasks included mathematical problem-solving, logical reasoning, and answering questions that required synthesizing information from multiple sources. This series of intermediate steps, which the authors termed "chain of thought," forms the core of CoT prompting.
The Paradigms of CoT Prompting
- Zero-Shot-CoT: Just add "Let's think step by step" to your question. This helps the AI break down big problems into smaller, easier parts. It's like showing your work in math class instead of just giving the final answer.
- Auto-CoT: This is an automatic way to make the AI explain its thinking. It works by:
- Grouping similar questions together.
- Picking one example from each group.
- Using these examples to help the AI learn how to explain its answers for new questions.
Let’s picture the CoT paradigms using this example:
"A farmer has 48 apples. He sells 20 and divides the remaining apples equally among 4 baskets. How many apples are in each basket?"
-
Zero-Shot-CoT:
Method: Provide a generic prompt like "Let's think step by step" with no specific examples. Relies solely on the LLM's inherent reasoning abilities.
Example Response: "The farmer starts with 48 apples. He sells 20, so 48 - 20 = 28 apples remain. These are divided into 4 baskets, so 28 / 4 = 7 apples per basket."
Outcome: Simple to implement, but can lead to errors if the LLM doesn't grasp the necessary reasoning steps. -
Auto-CoT:
Method: The LLM automatically generates its own demonstrations by clustering similar questions and using prompts to create reasoning chains, automating the demonstration creation process.
Auto-generated Demonstration: "A baker has 30 cookies. She sells 12 and divides the rest equally among 3 boxes. How many cookies are in each box? First, 30 - 12 = 18 cookies remain. Then, 18 / 3 = 6 cookies per box."
Example Response (Farmer Problem): "Following the example, first we subtract the sold apples: 48 - 20 = 28. Then, we divide by the number of baskets: 28 / 4 = 7. So, there are 7 apples in each basket."
Outcome: Offers more guidance and typically improves accuracy, though implementation can be more complex.
Current progress in CoT research
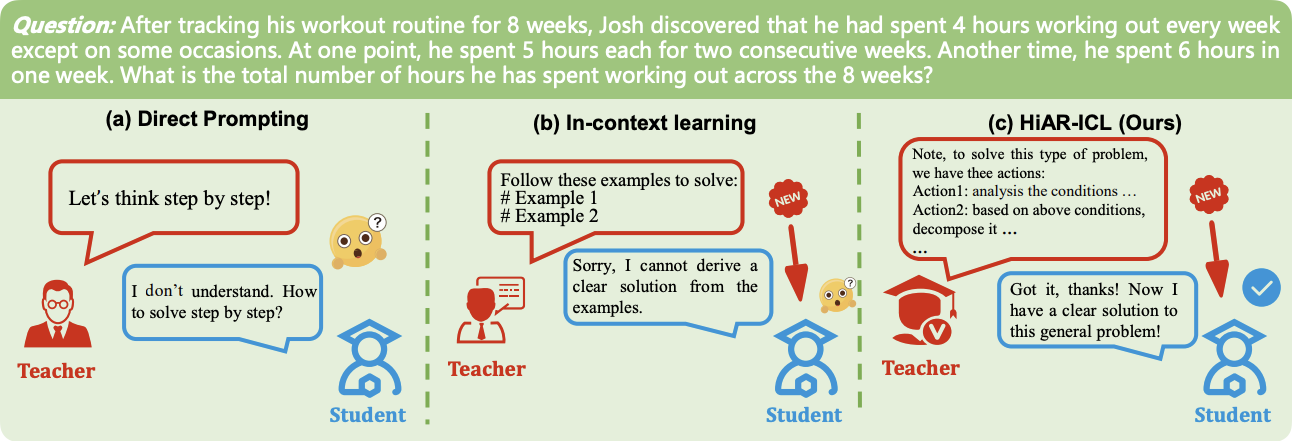
Current CoT paradigms suffer from a critical dependence on the quality, quantity, and specific characteristics of the provided demonstrations. LLMs are highly sensitive to even minor variations in example presentation, ordering, and labeling, meaning suboptimal examples can severely limit performance.
Furthermore, creating effective demonstrations often necessitates significant human expertise, a costly and time-consuming hurdle, especially for complex domains like mathematics. Finally, Auto-CoT sometimes may struggle to generalize; even structurally similar problems require new demonstrations if the presentation format changes, hindering its adaptability.
A High-level Automated Reasoning paradigm in In-Context Learning (HiAR-ICL) improves by shifting from providing specific examples to teaching general reasoning skills. It uses "thought cards," representing abstract reasoning patterns generated by Monte Carlo Tree Search (MCTS), as the new form of "context." These thought cards, composed of fundamental reasoning actions like problem decomposition, guide the LLMs' problem-solving process.
A complexity metric selects the most relevant thought cards for a given problem, and the LLM's solution is then rigorously verified using reward models and consistency checks. Experiments show that HiAR-ICL surpasses existing methods in accuracy and efficiency on complex reasoning tasks.
Importance of CoT in LLM's reasoning ability
Improved Accuracy: Decomposing problems into smaller steps allows for better error detection and correction, leading to more accurate results, especially in inherently multi-step tasks like math and logic puzzles.
Enhanced Interpretability/Transparency: The explicit reasoning steps make the LLM's decision-making process clear and understandable, building trust and even debugging.
Promotes Attention to Detail: The step-by-step approach encourages a deeper understanding of the problem, similar to detailed educational explanations.
Example for CoT
o1-preview and o1-mini serve as excellent examples of Chain-of-Thought (CoT) reasoning because they showcase its adaptability across different complexity levels and resource constraints:
- Structured Reasoning Across Complexities: Both models break down problems into smaller, manageable steps, a core principle of CoT. o1-mini handles simpler, linear reasoning tasks effectively, while o1-preview tackles multifaceted problems requiring multi-step and contextual reasoning.
- Tailored Application: o1-mini demonstrates CoT's efficiency in resource-constrained environments by focusing on clear, methodical reasoning for less complex tasks. o1-preview showcases CoT's scalability for advanced reasoning where deep contextual understanding is crucial.
- Illustrative Trade-offs: The two models highlight inherent CoT trade-offs. While o1-mini prioritizes efficiency for simpler tasks, o1-preview emphasizes depth and complexity handling, illustrating how CoT can be tailored to specific needs.
- Broad Applicability: Their use in debugging, research, and content creation demonstrates CoT's versatility across domains, from straightforward tasks to intricate problem-solving.
- Educational Value: o1-mini offers an accessible entry point for understanding CoT's step-by-step approach, while o1-preview demonstrates its potential for advanced applications, inspiring further exploration and development of CoT in specialized fields.
Conclusion
OpenAI's O1 models are considered groundbreaking, potentially revolutionizing complex, multi-step AI applications similar to how GPT-4 spurred advancements in language processing. These models represent a shift towards deliberate, goal-oriented reasoning, ideal for intricate planning tasks.
Although early in development, they foreshadow future AI systems where such reasoning models collaborate with faster execution models. For prompt engineering advice and workflow integration guidance, experts are available to provide tailored support to researchers and users.


