Keywords AI
All about LLM evaluating
In today's tech-driven world, Large Language Models (LLMs) are increasingly vital. By 2025, an estimated 750 million apps will utilize LLMs, significantly boosting content generation and efficiency.
As the reliance on LLMs grows, so does the need to control and improve the quality of their outputs. One innovative approach to achieving this is using LLMs as evaluators, or "LLM-as-a-judge."
In this blog, we’ll delve into 3 essential LLM evaluation metrics and introduce frameworks and platforms you can use to assess the performance of your LLMs effectively.
3 Essential LLM evaluation metrics
Correctness
Correctness assesses how accurately the generated answer matches the ground truth, considering both semantic and factual similarities. Key metrics include ROUGE-L, Token Overlap, and BLEU, which collectively measure precision, recall, and F1 score.
Answer Relevancy
Answer relevancy evaluates the pertinence of the generated answer to the given prompt, with higher scores for more relevant responses. This metric considers the question, context, and answer to ensure the output is informative and concise.
Hallucination
Hallucination determines if the LLM output contains made-up information, while faithfulness measures the factual consistency of the answer against the given context. An answer is deemed faithful if all its claims can be inferred from the context, with higher scores indicating better faithfulness.
Conventional Evaluation Scores
- BLEU (Bilingual Evaluation Understudy): The BLEU scorer evaluates the output of your LLM application against annotated ground truths (expected outputs). It calculates the precision for each matching n-gram (n consecutive words) between the generated and expected outputs, determining their geometric mean and applying a brevity penalty if needed.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE evaluates text summaries by comparing n-gram overlaps between LLM outputs and expected outputs. Key variants include ROUGE-L, which measures the longest common subsequence (LCS) reflecting sentence-level word order; ROUGE-N, which assesses unigram, bigram, trigram, and higher-order n-gram overlap; and ROUGE-S, which evaluates skip-gram concurrence allowing for arbitrary gaps between words. These metrics provide a comprehensive evaluation of text similarity and relevance.
- BERTScore: it leverages pre-trained contextual embeddings from BERT to match words in candidate and reference sentences by cosine similarity. Emerging as an alternative to traditional evaluation metrics, BERTScore is particularly useful for evaluating the quality of text summarization by measuring the similarity between the text summary and the original text.
LLM-as-a-judge
Evaluating LLM outputs programmatically can be challenging due to a lack of good metrics, especially for generative tasks. LLM-as-a-Judge leverages LLMs to score outputs, offering an alternative to human labels when programmatic evaluation is difficult. This method is particularly useful for detecting hallucinations, assessing correctness, and identifying toxic or inappropriate answers.
LLM-as-a-Judge uses LLMs to evaluate outputs based on criteria such as accuracy, toxicity, and hallucinations. The process involves creating evaluation prompts, selecting a suitable LLM, and generating evaluations across datasets. This approach provides consistent assessments, accelerates the iteration process, and enables quick refinements without manual annotation.
Evaluation frameworks
- Relari AI: Relari AI (YC W24) develops testing and simulation tools for GenAI applications, including the continuous-eval framework and a cloud platform for synthetic data and auto-evaluators. Ragas: A framework that helps us evaluate our Retrieval Augmented Generation (RAG) pipeline
- Ragas: A framework that helps us evaluate our Retrieval Augmented Generation (RAG) pipeline
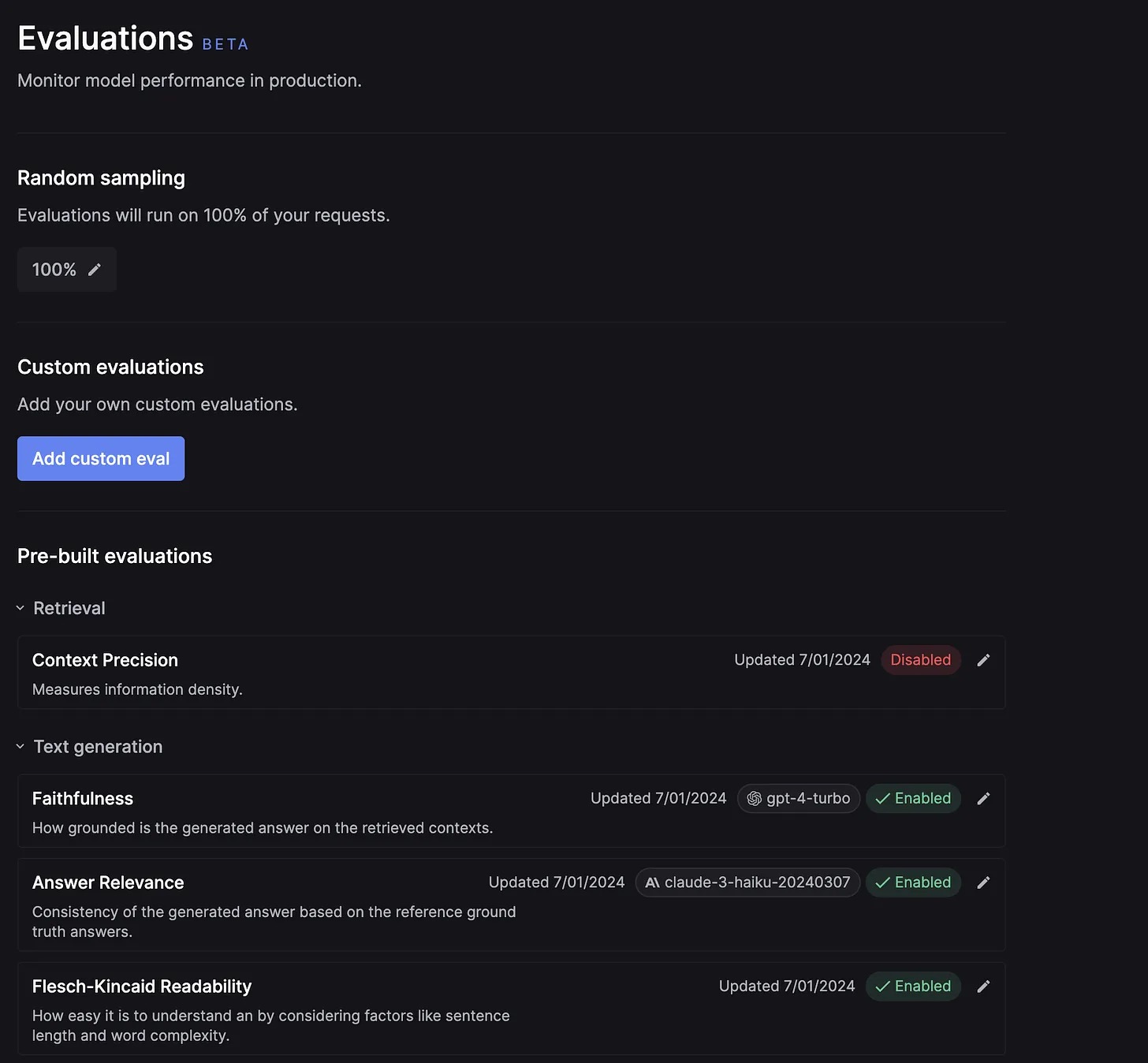
LLM Evaluation platforms
[Keywords AI]{https://keywordsai.co} offers a comprehensive platform that integrates Relari AI, providing both an evaluation framework and observability. This platform allows you to choose from existing metrics or create your own to evaluate LLM outputs.
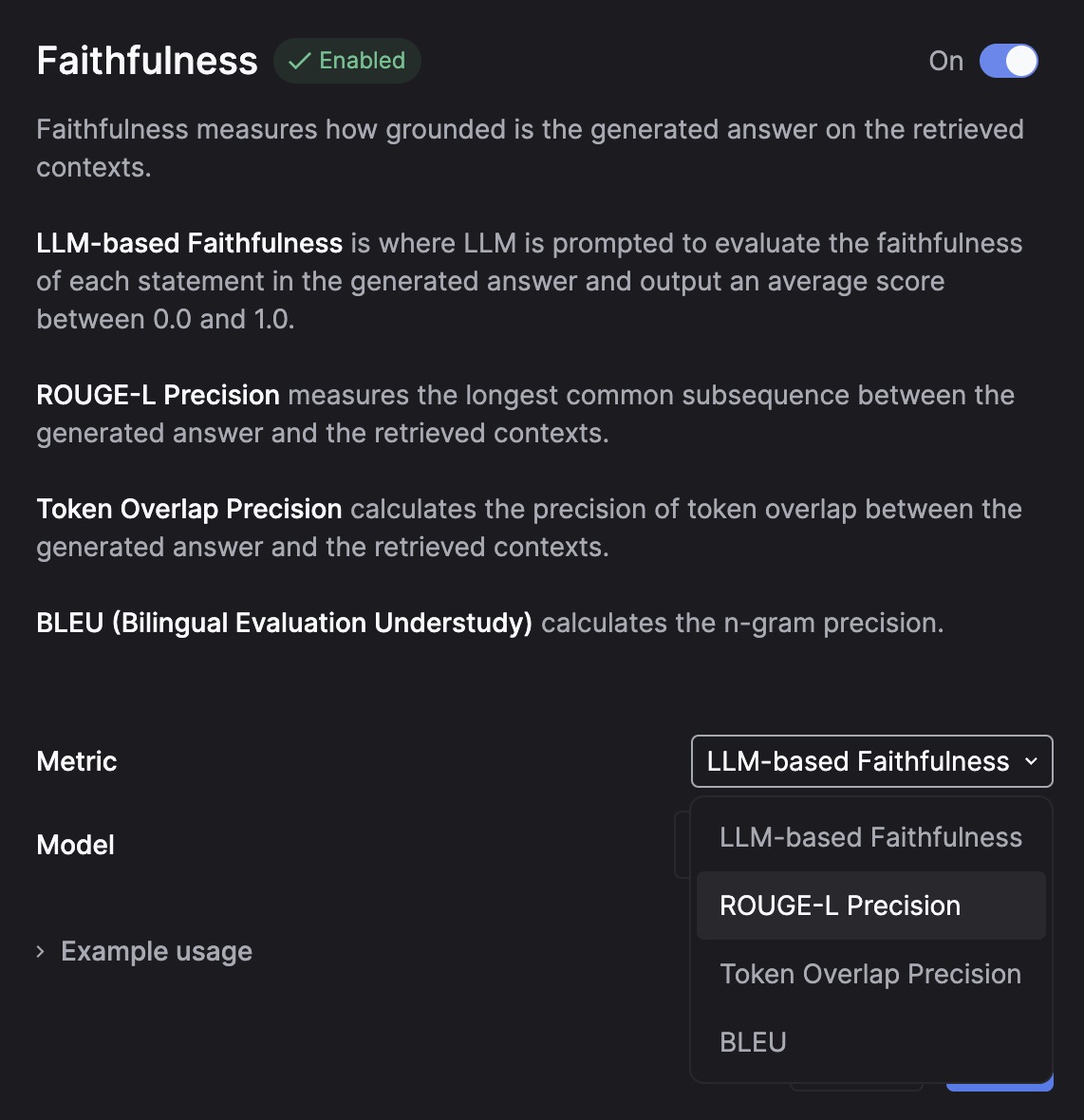
You can select any model to evaluate your LLM output or use conventional evaluation methods.
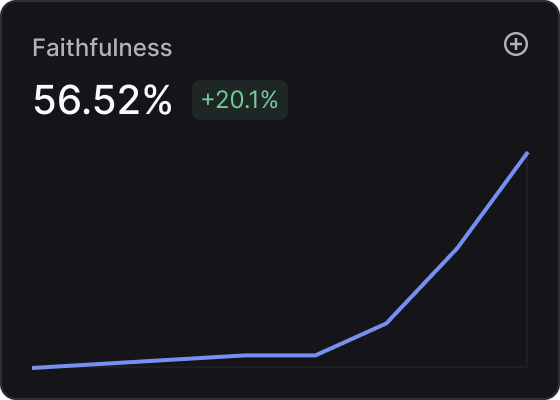
You can also monitor your LLM's performance through evaluation graphs displayed on the dashboard.