Keywords AI
How to stop LLM hallucinations?
What are LLM hallucinations?
Hallucinations in LLMs occur when they generate incorrect, nonsensical, or irrelevant content. These issues arise from the models' reliance on statistical patterns rather than true understanding, leading to misinformation and reducing trust in their outputs. Addressing these hallucinations is crucial for improving the accuracy and reliability of LLMs.
Why LLMs hallucinate
- Ambiguous Prompts: When prompts are too broad or vague, LLMs may misinterpret the user's intentions, leading to irrelevant or incorrect content generation.
- Insufficient Training Data: LLMs trained on small or low-quality datasets may lack a robust understanding of language relationships, leading to inaccurate or irrelevant outputs.
- Lack of domain knowledge: LLMs may produce hallucinations when they encounter topics outside their training data's scope, leading to gaps in understanding and erroneous information.
How to detect LLM hallucinations?
- Human evaluation: Manual review by people can effectively identify inaccuracies and irrelevant information in LLM outputs. However, this method is time-consuming and subject to human bias, making it less practical for large-scale evaluations.
- LLM-as-a-Judge: An LLM evaluates another LLM's outputs by measuring consistency or rating them on a scale. This automates detection but depends on the evaluator model's accuracy.
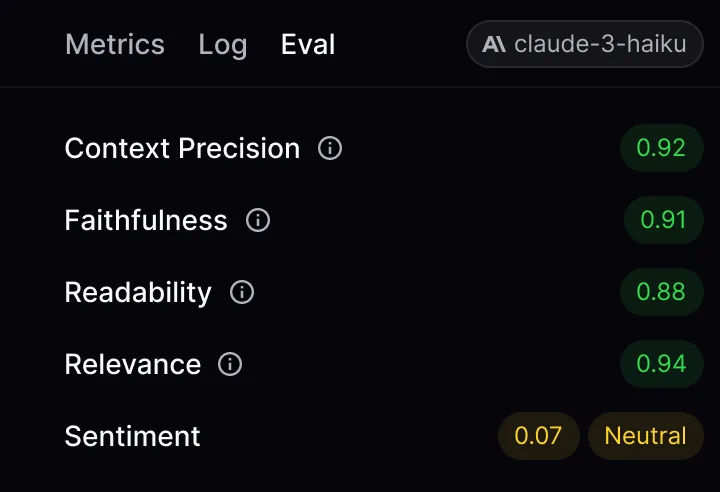
Ways to Stop LLM Hallucinations
- Advanced Prompting
- Retrieval Augmented Generation (RAG)
- Fine-tuning
Advanced Prompting
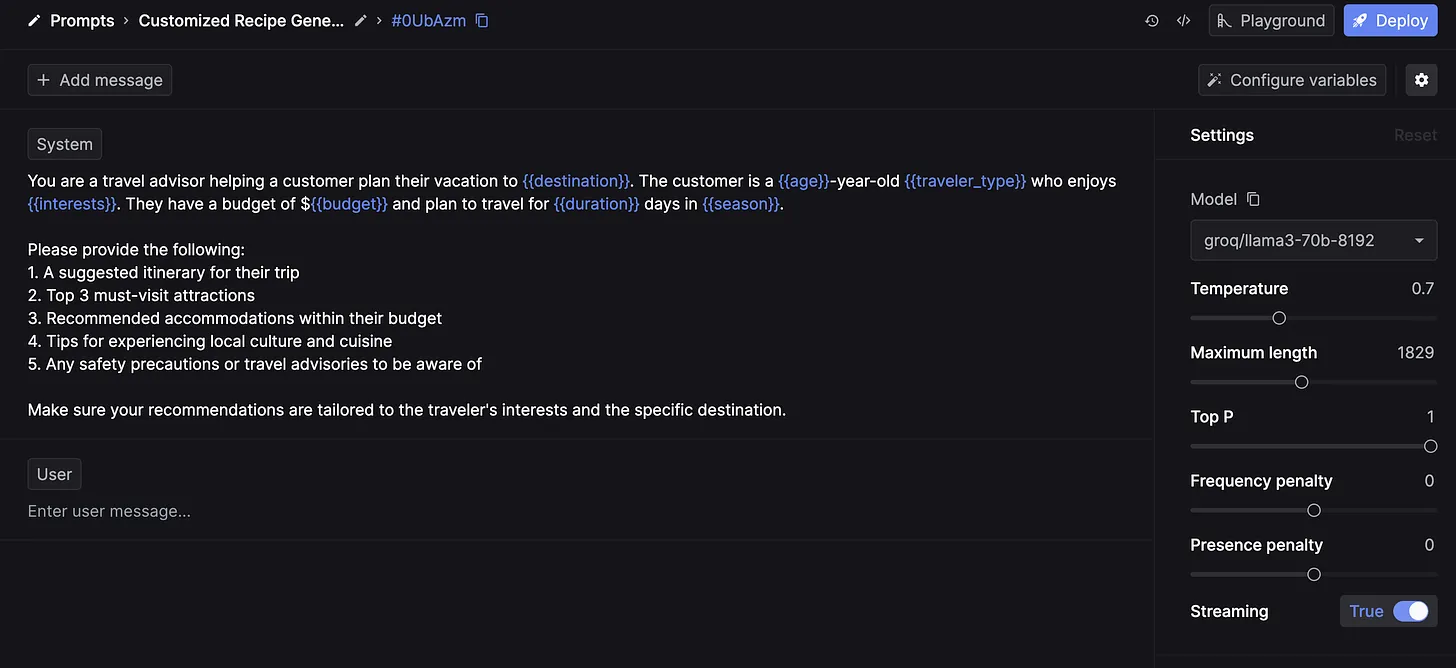
Advanced prompting techniques guide LLMs to generate more accurate and coherent responses. Using specific, detailed prompts helps reduce irrelevant or incorrect outputs. Instructional prompts with clear examples of the desired format and style further align the model's responses with the expected outcome.
Prompt engineering, the design, and refinement of instructions is crucial for reliable results. Explicit instructions and contextual cues in prompts reduce ambiguity, while system prompts like "Please only provide accurate and verifiable information" ensure the model produces trustworthy content.
Utilizing prompt management tools can also be beneficial for creating high-quality prompts. There are many such tools available that effectively test and refine prompts, helping to achieve the best possible results.
Retrieval Augmented Generation (RAG)
Retrieval-augmented generation (RAG) enhances the accuracy and relevance of LLM outputs by combining generative capabilities with information retrieval methods. This approach grounds the model's responses in real, verifiable data, reducing the likelihood of hallucinations.
Despite its benefits, challenges remain in ensuring LLMs do not produce content misaligned with the retrieved information. Tools like the Retrieval-Augmented Generation Benchmark (RGB) and RAGTruth are instrumental in addressing these challenges, helping quantify and minimize hallucinations by providing comprehensive evaluation frameworks.
RAG is particularly useful in applications such as question-answering chatbots, search engines, and knowledge bases, where accuracy and context awareness are crucial. RAG ensures real-time accuracy and relevance in responses by integrating a retrieval system that searches a vector database for relevant data. This method also includes extending prompts with additional context from databases or APIs, further reducing hallucinations and enhancing the reliability of LLM outputs.
Fine-Tuning
Fine-tuning adjusts the learned patterns of an LLM to align closely with the specific nuances, vocabulary, and factual information of a new context, improving accuracy and relevance. By training the LLM on a curated dataset, fine-tuning updates its knowledge base, mitigating the propagation of errors or outdated information from its broader pretraining.
This process enhances the model's ability to generate factually correct, contextual, and coherent responses within a specific domain, significantly reducing the likelihood of hallucinations.
Fine-tuning is particularly effective for standardized tasks with sufficient training data. It involves collecting many high-quality prompt/completion pairs and experimenting with different foundation models and hyperparameters, such as learning rate and number of epochs, to achieve the best results for your use case. This focused approach refines the model’s precision and minimizes its tendency to generate incorrect or baseless information, ensuring more reliable outputs.
Conclusion
To effectively address LLM hallucinations, it's essential to tackle root causes such as ambiguous prompts, insufficient training data, and gaps in domain knowledge. Detection methods like human evaluation and LLM-based assessment offer varying degrees of reliability and scalability.
Mitigation strategies involve advanced prompting for clarity, retrieval augmented generation (RAG) to bolster accuracy with external data, and fine-tuning to tailor models to specific contexts, collectively enhancing the reliability and trustworthiness of AI-generated outputs.


