Keywords AI
o1-preview vs. claude-3.5-sonnet: Comparing top LLMs
Today (Sep 12, 2024), OpenAI unveiled its latest language model, o1-preview. This advanced model is engineered to dedicate more time to processing before generating responses, enabling it to tackle complex tasks and solve challenging problems in science, coding, and mathematics with enhanced capabilities.
In this blog post, we'll thoroughly analyze o1-preview and compare it to Claude 3.5 Sonnet, which was previously considered one of the most advanced models available.
Comparison Methodology
Our analysis utilizes Keywords AI's LLM playground, a platform that supports over 200 language models and offers function-calling capabilities. We'll explore the following aspects:
- Basic comparison
- Benchmark comparison
- Processing speed
- Performance comparison
- Suggested use cases
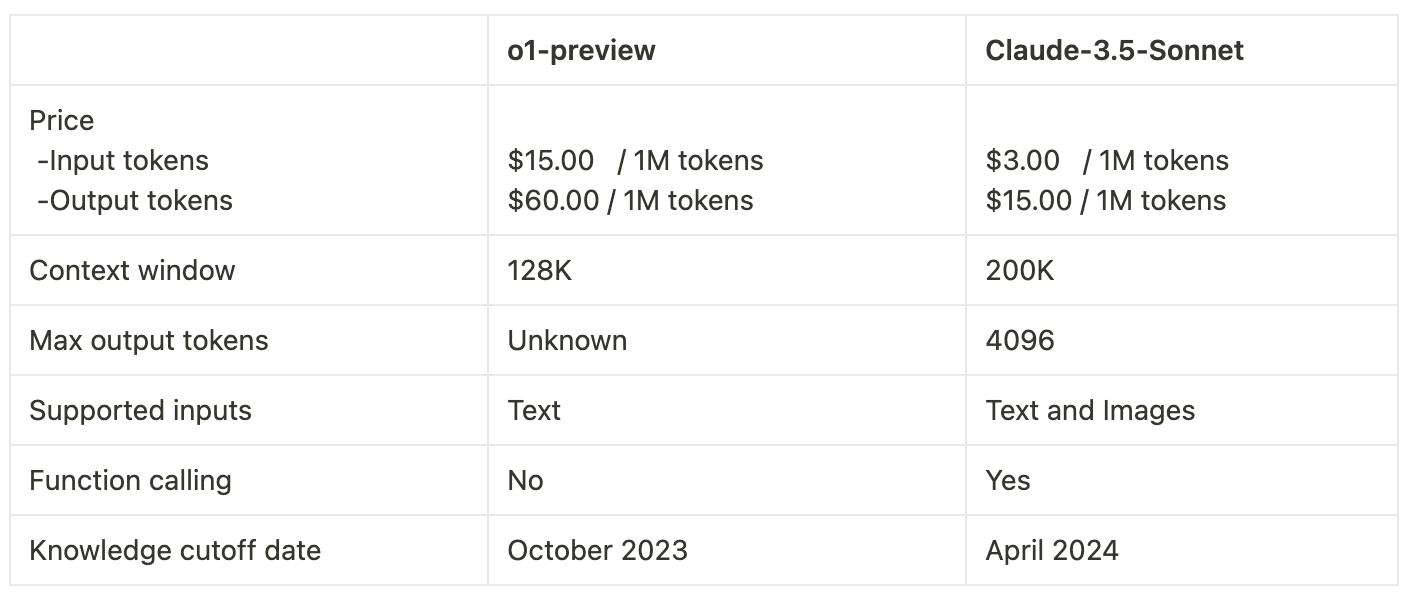
Basic Comparison
Note: o1-preview doesn’t support Streaming, function calling, and system messages.
Benchmark Comparison
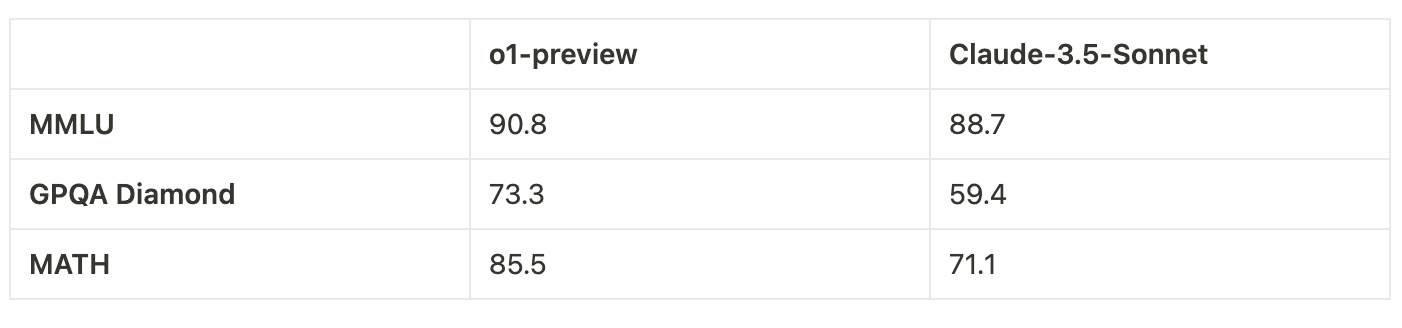
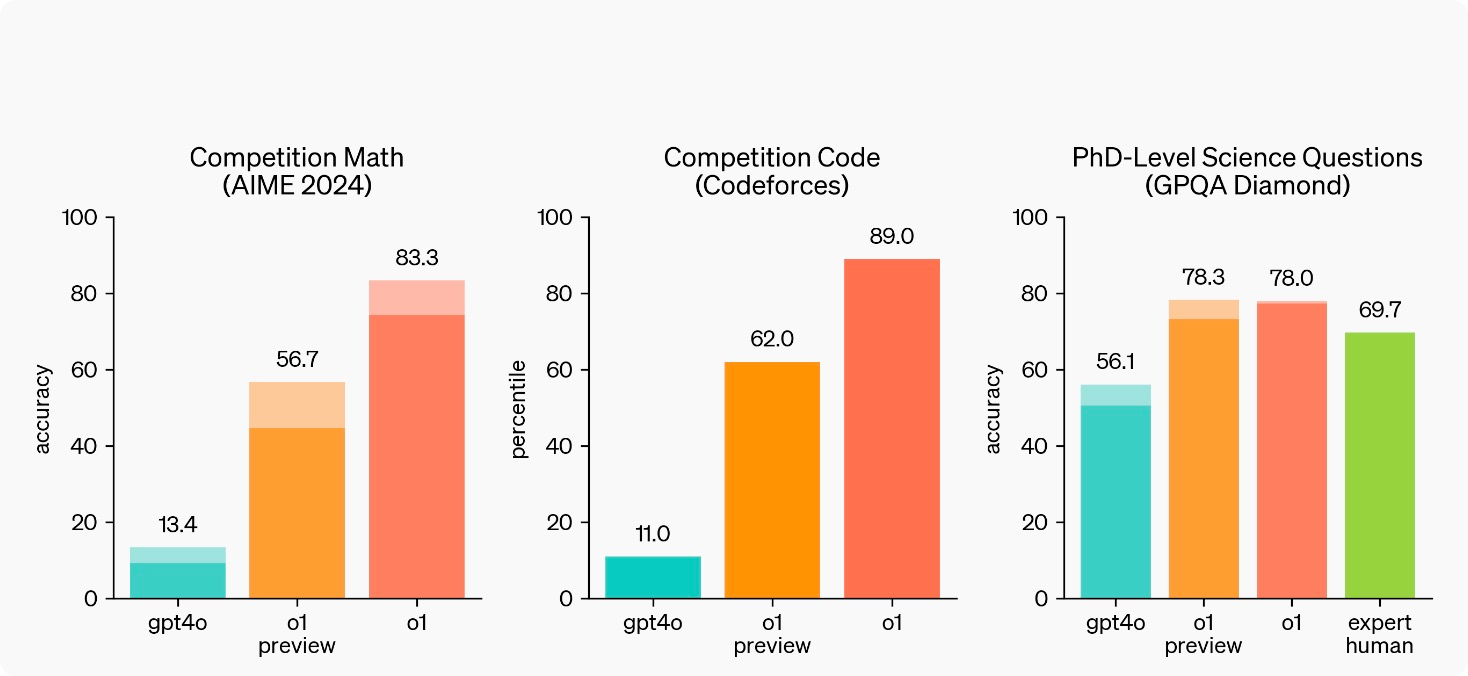
O1-preview outperforms Claude 3.5 Sonnet across all benchmarks. The smallest gap is in MMLU (general knowledge). GPQA Diamond, testing graduate-level reasoning, shows a significant performance difference. The MATH benchmark reveals the largest gap, highlighting o1-preview's advanced mathematical capabilities. These results indicate o1-preview's substantial improvements in complex reasoning and problem-solving across various domains.
Speed Comparison
O1-preview takes longer to think and respond than other LLMs. While direct speed comparisons may not be entirely fair, testing o1-preview's speed is crucial. This information helps developers better understand o1-preview's capabilities and determine if it's suitable for their projects.
Note: As o1-preview doesn't support streaming, we disabled streaming for both models. Consequently, time to first token (TTFT) couldn't be measured.
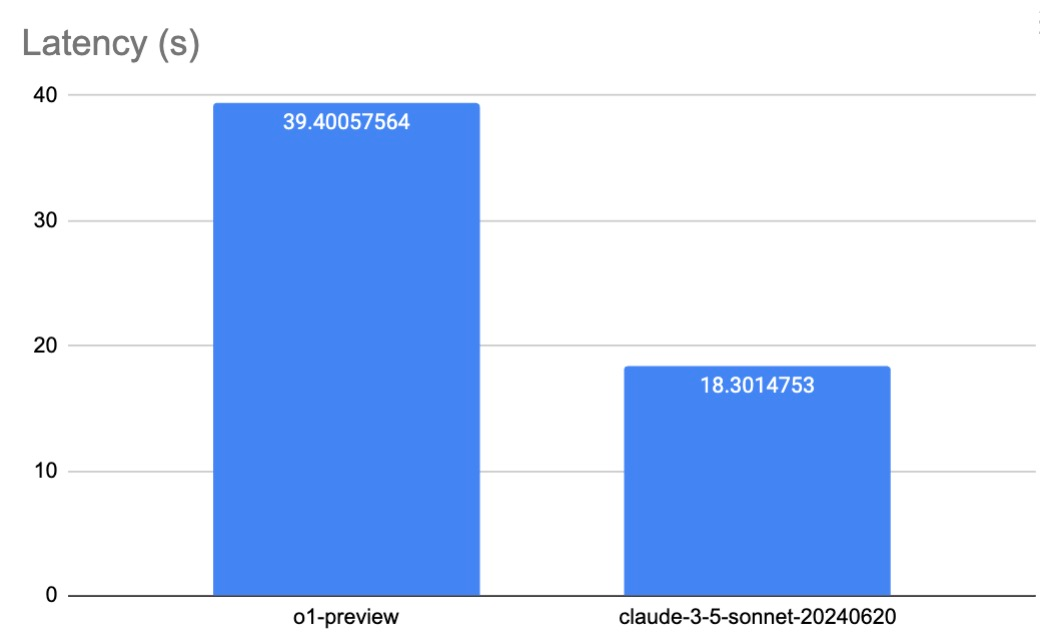
Latency
Our tests, involving hundreds of requests per model, revealed significant differences. Claude 3.5 Sonnet averages 18.3s/request, whereas o1-preview takes 39.4s/request. O1-preview's significantly longer latency is due to its extended thinking and reasoning process.
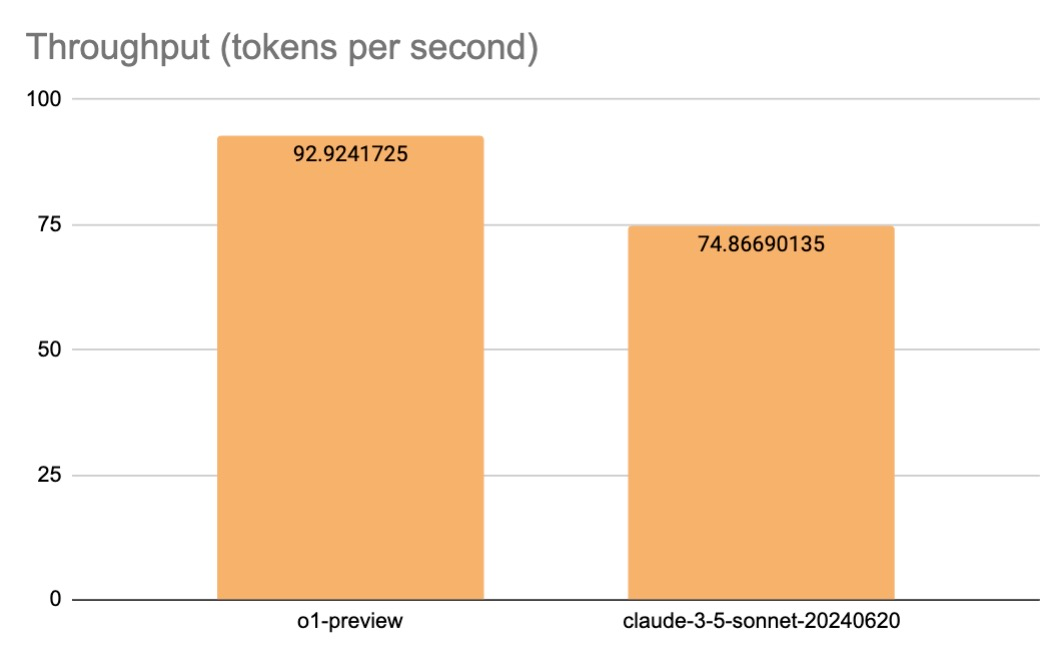
Throughput (Tokens per second)
Despite higher latency, o1-preview shows superior throughput. O1-preview generates 92.94 tokens/second, while Claude 3.5 Sonnet produces 74.87 tokens/second. This indicates that o1-preview's longer generation time is primarily due to its initial processing phase rather than token generation speed.
Performance comparison
We conducted evaluation tests on the Keywords AI platform. The evaluation comprised three parts:
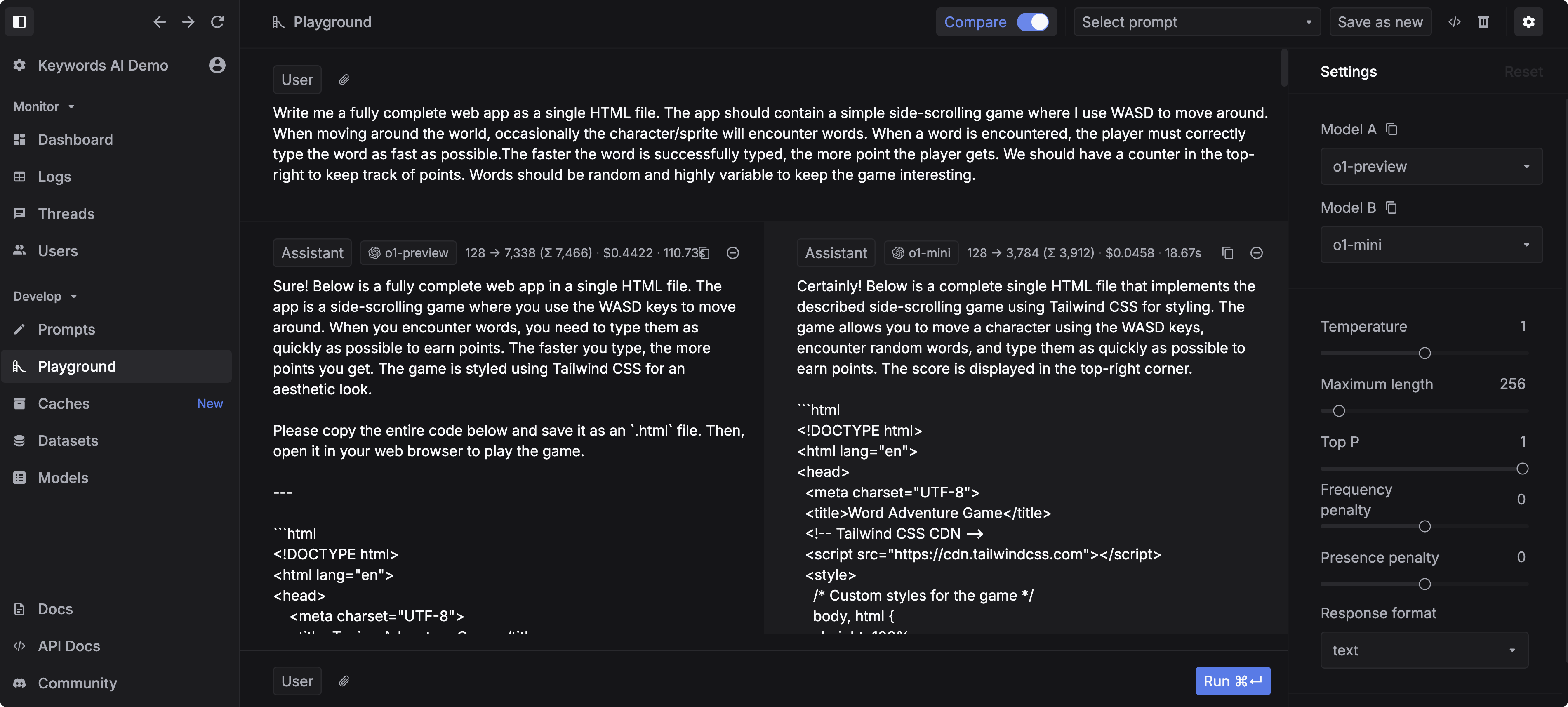
- Coding Task: Both models successfully completed frontend and backend development tasks. o1-preview demonstrated superior performance with longer contexts, identifying and resolving bugs more efficiently in the first attempt. It also exhibited a more thorough code analysis capability.
- Logical Reasoning: o1-preview excels in reasoning tasks. Its thinking process closely mimics human cognition. While Claude 3.5 Sonnet performs well on most problems, o1-preview consistently solves complex reasoning challenges, including International Mathematical Olympiad (IMO) level problems.
- Writing Task: Both models perform exceptionally well on writing tasks. They demonstrate the ability to craft genuine, personalized cold emails, as well as concise and meaningful blog posts.
Suggested Use Cases
o1-preview
- Best for: Complex problem-solving in mathematics, coding, and physics. Particularly suited for researchers tackling challenging tasks.
- Not suitable for: AI applications requiring rapid response times or heavily reliant on system prompts. Voice AI applications due to lack of streaming support.
Claude 3.5 Sonnet
- Best for: Most AI applications requiring problem-solving capabilities and high-quality content generation.
- Not suitable for: Voice AI applications or projects with strict budget constraints requiring lower operational costs.
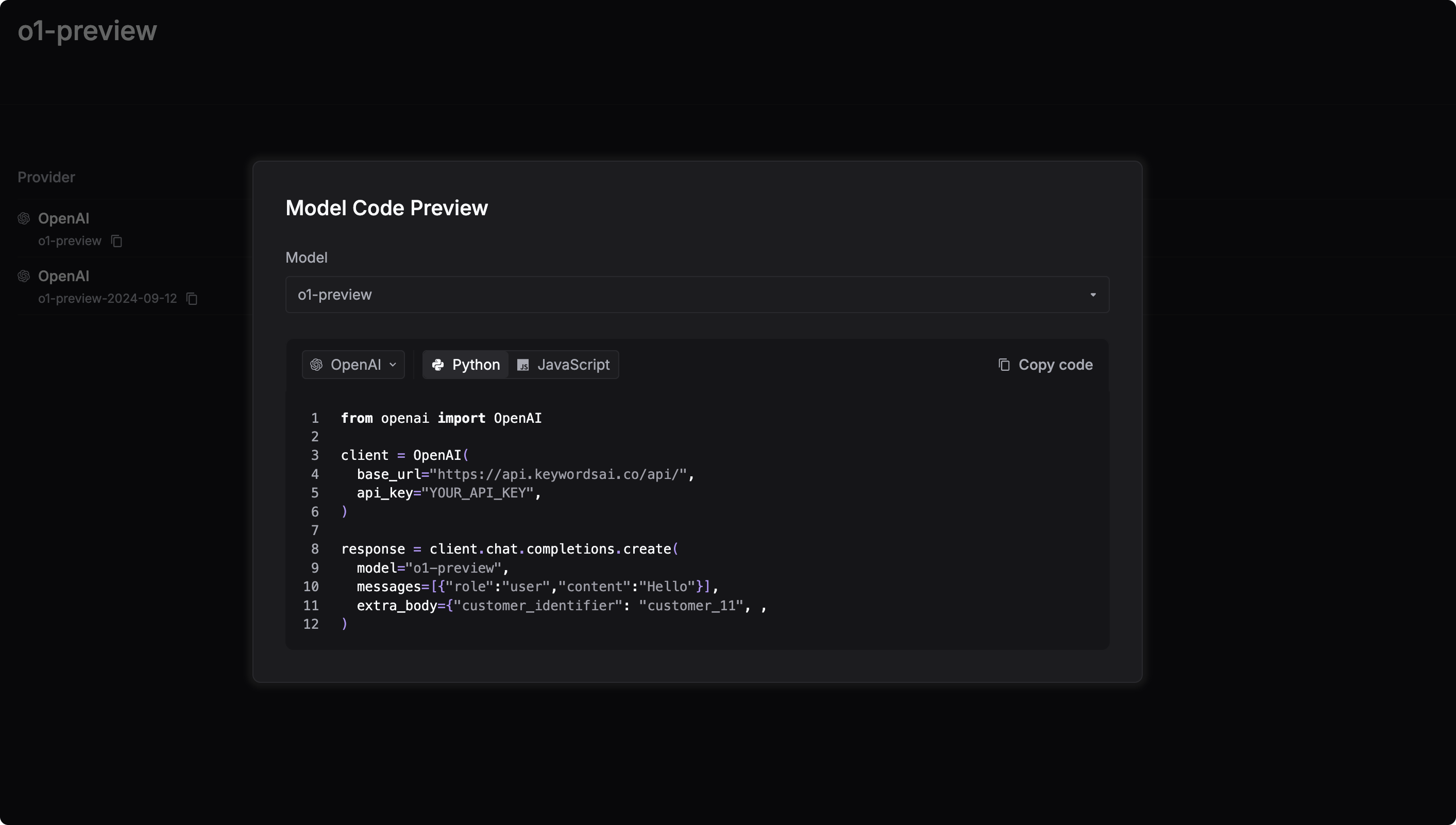
How to integrate o1-preview into your AI apps.
To incorporate o1-preview into your AI applications, simply visit the Keywords AI model page and locate the "View code" button. Click this button to copy the provided code snippet, then paste it directly into your codebase. With this straightforward process, you'll be ready to harness the power of o1-preview in your projects, enabling you to tackle complex problems and generate high-quality content with ease.