Keywords AI
95% of LLM developers are missing these 3 key reliability setups
AI has become the hottest topic for startups and investors, largely due to the rapid development of Large Language Models (LLMs). Major providers like OpenAI, Anthropic, and Google are releasing new models almost monthly, leading to a surge in LLM-based applications. Alongside this growth, numerous tools have emerged to help developers build LLM products more quickly and easily. Developers can now use OpenAI's Assistant API to create AI assistants, LangChain to construct AI agents, and various frameworks to develop autopilots.
However, most tools in the market focus solely on enabling developers to build LLM products, without offering any reliability assistance. As a result, developers often need to rely on third-party services or create their own reliability setups to ensure their LLM apps maintain high uptime and reliability.
In this blog, we'll explore three key reliability setups that LLM developers are often overlooking. We'll discuss how to implement these setups or build your own solutions quickly and effectively.
LLM App Reliability: Key Metrics
To measure an LLM application's reliability, developers should focus on three crucial metrics:
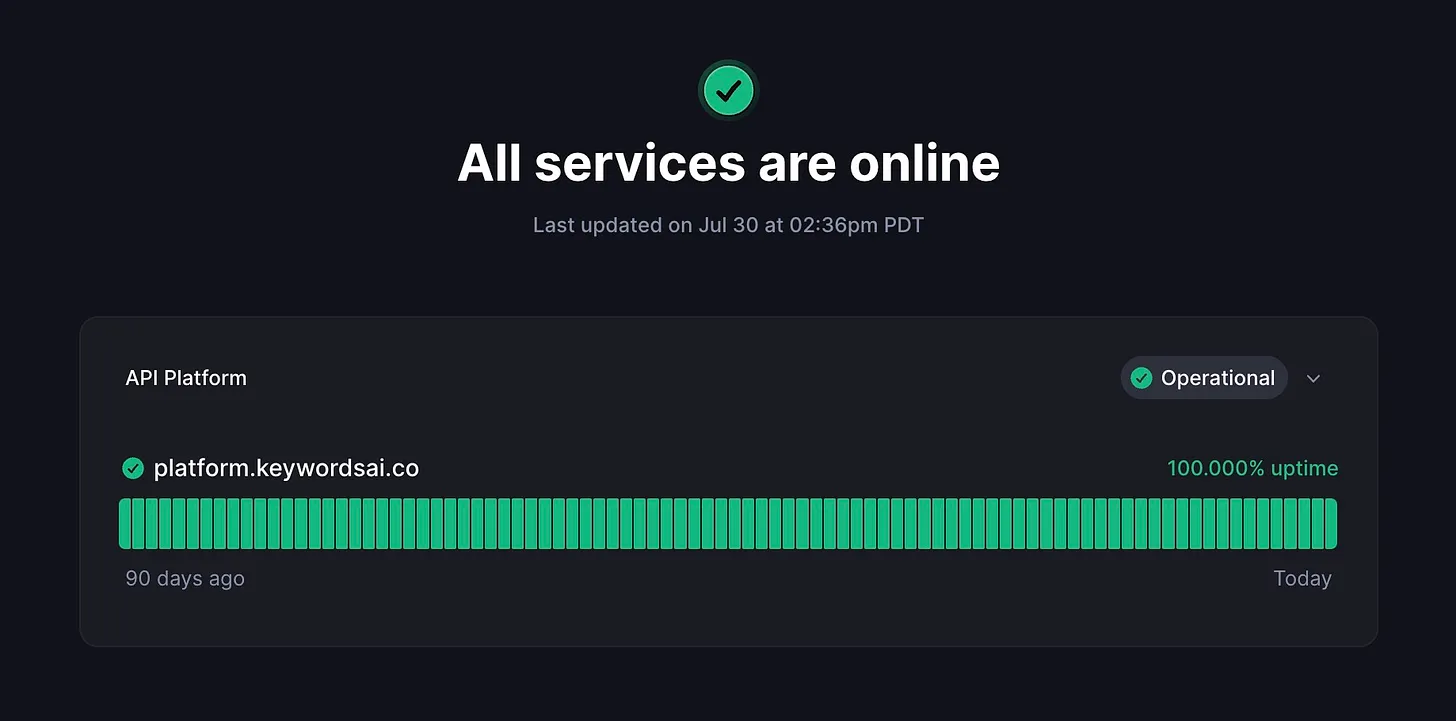
Uptime: Critical for all products, not just LLM applications. Uptime directly impacts user retention. If an application experiences significant downtime, users will likely abandon it. The current industry standard for LLM application uptime should be at least 99.95%.
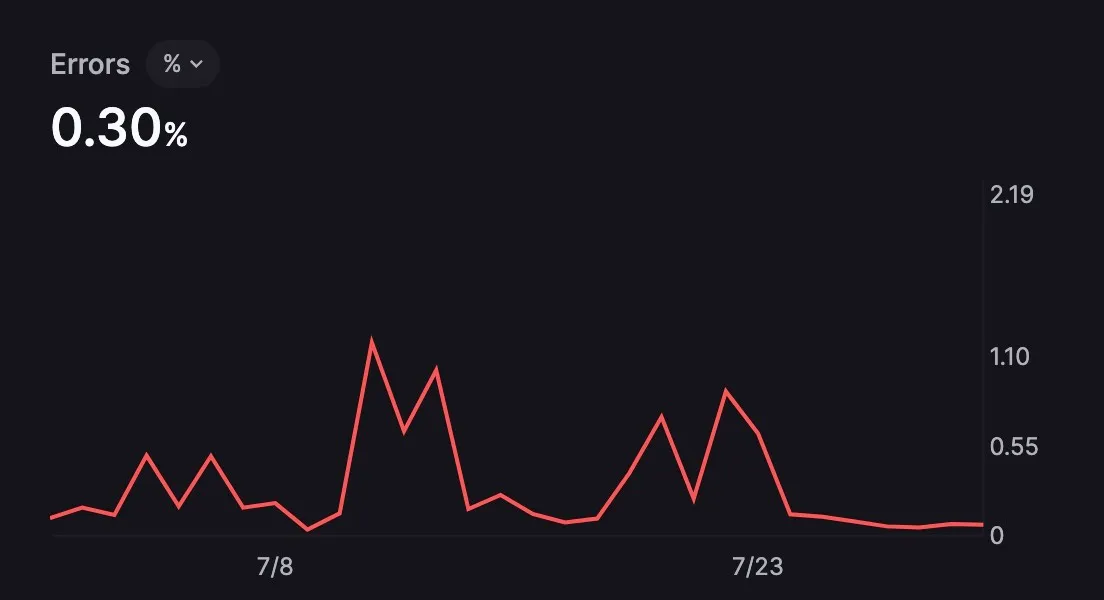
Error rate: This metric represents the number of errors that occur per 100 requests sent to LLMs. For example, an error rate of 5 means that 5 out of every 100 requests result in an error. Errors can stem from various sources:
- Instability of upstream providers (e.g., OpenAI)
- Incompatibility between tool frameworks and providers
- Mismatches between developers' use cases and LLM capabilities (e.g., sending an image to a text-only LLM)
- Exceeding rate limits due to high request volumes to a single model/provider
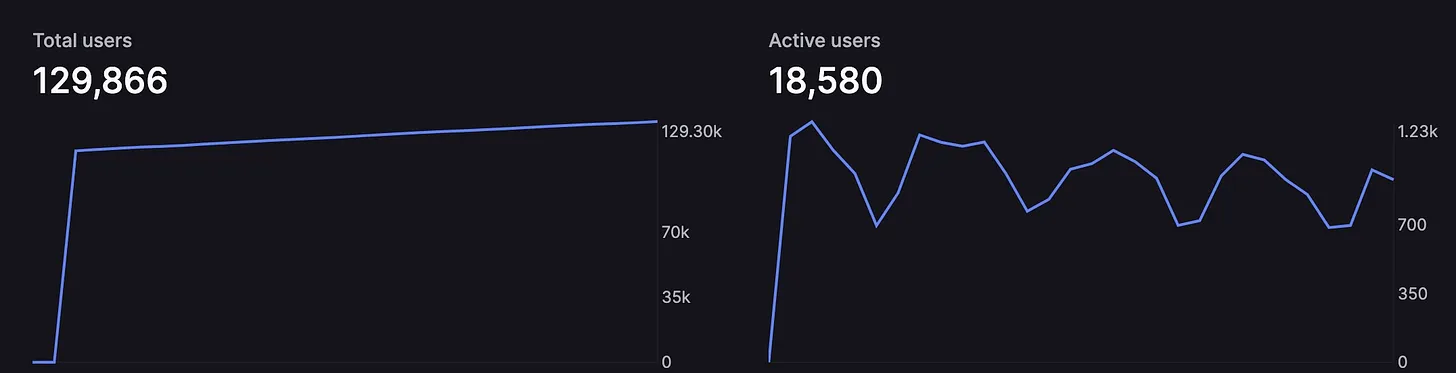
User churn rate: With thousands of new LLM applications entering the market daily, competition is intensifying rapidly. Developers may see a surge in users one day, only to lose them the next. Monitoring user activity and understanding the churn rate is essential for any developer aiming for long-term success.
Reliability setup
Implementing an alert system
An alert system is crucial for all products, including LLM applications, regardless of whether they operate in real-time. Timely notifications allow for swift problem resolution. Consider the following components:
- Uptime monitoring platforms: Set up an uptime page for your apps to track availability and enhance credibility for potential users. For example, Better Stack offers a simple sign-up process for a unique uptime page and provides downtime notifications.
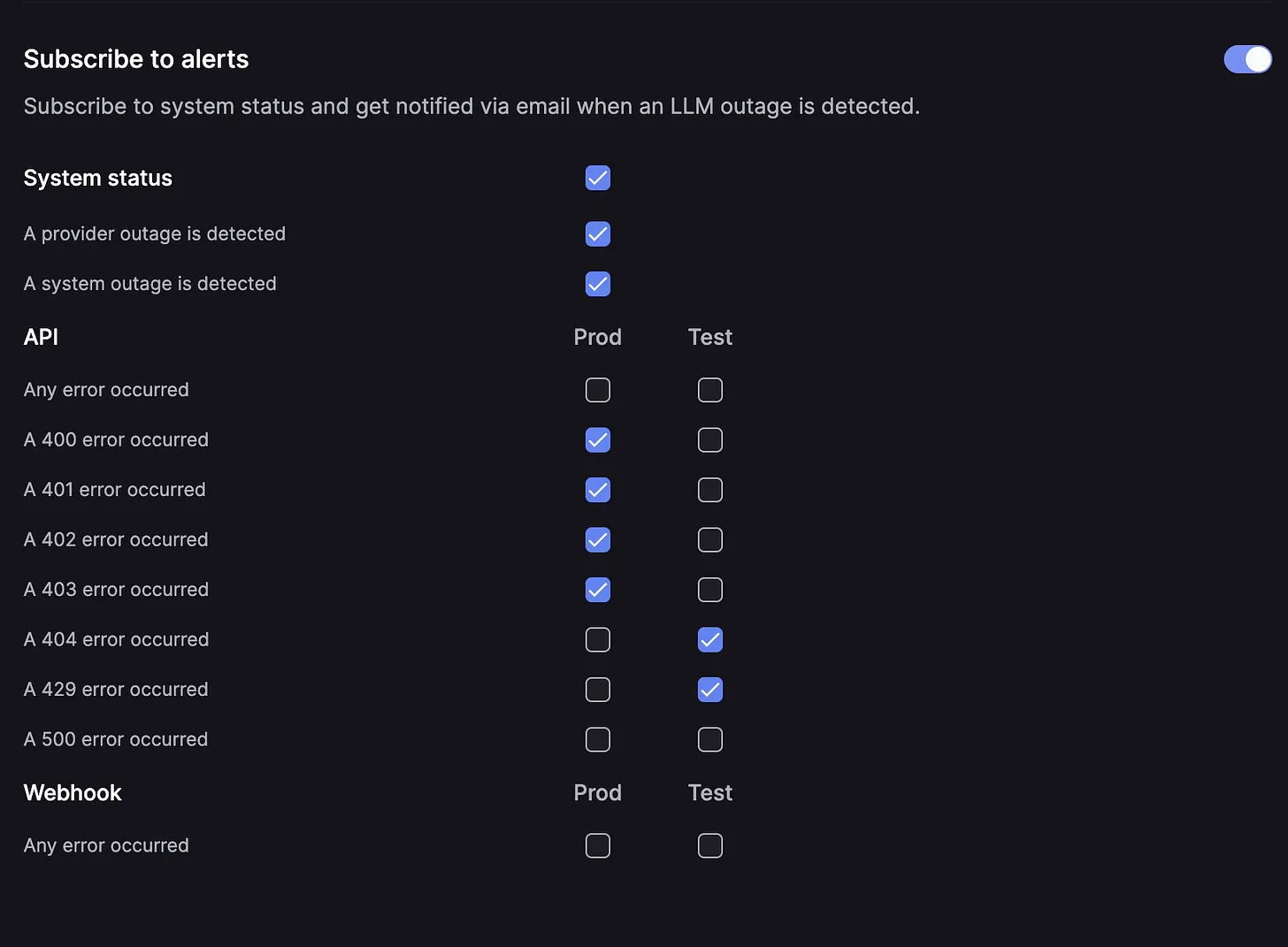
- All-in-one alert system: This goes beyond simple system status monitoring, addressing LLM-specific issues like provider outages, API errors (400/404), and webhook failures. You can build your own using frameworks like Django for email notifications, or utilize specialized services like Keywords AI's all-in-one alert system for customizable LLM-specific alerts.
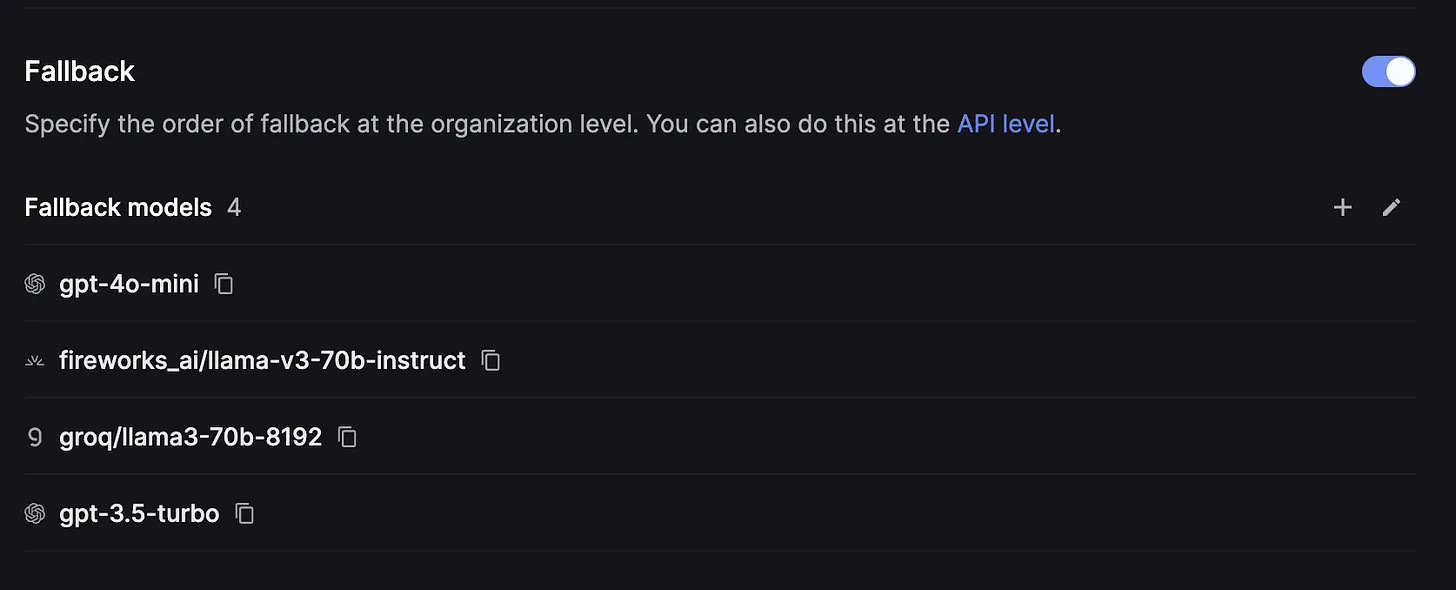
Setup fallbacks
Fallback is crucial when you encounter errors from your primary model. It allows you to switch to another model seamlessly, without users experiencing any errors. This is vital for ensuring a great user experience - nobody wants to waste time on AI apps that constantly generate errors. For instance, if you're using OpenAI's API to call models like GPT-4o or GPT-4 Turbo, you might notice frequent incidents and elevated error rates. Your job is to handle all of this in your backend, ensuring users never see these errors.
Ways to implement a fallback system:
- Build your own: Integrate models from different providers. If you're using Google's Gemini 1.5 Flash, consider also integrating Claude 3 Haiku and GPT-4 Mini into your product. They offer similar performance! The quickest way is to use an LLM gateway to access these models with a consistent format. Check out the LLM gateway provider. Then you could try to catch the exceptions and then switch to other models.
- Choose a third-party fallback system: While you could build everything in your backend, it might take many hours of work. Alternatively, the fallback system on Keywords AI is super simple. Just add your desired fallback models on their website, and they'll handle all LLM outages for you. It takes just 1 minute to set up and ensures 0 seconds of downtime.
Increase LLM rate limits
No one can predict when a surge in demand will occur, but being prepared for this possibility is crucial. As a developer or startup founder, you should always dream big and have a robust plan in place to handle sudden spikes in usage. Here are two effective strategies to increase your LLM rate limits:
- If you have a substantial spending history with a provider, you can request a manual increase in your rate limits. While this option is viable, it typically requires significant expenditure and can be a slow process. Waiting for provider approval can result in downtime and potential loss of users. Therefore, while this method is viable, it shouldn't be your only line of defense.
- Load Balancing LLM Requests: A more dynamic and efficient approach is to load balance your LLM requests across different models or accounts. This method is straightforward and can be implemented with just a few lines of code. By distributing requests among various models or creating multiple accounts, you can handle large volumes of traffic seamlessly. For a detailed guide on how to implement load balancing, check out our article: How to Increase Your LLM Rate Limits for Free!.
Monitor your users.
While this isn't directly related to reliability setups, it's crucial for developers to understand the importance of user monitoring in maintaining a reliable LLM application. Knowing your users' behavior and inputs (with their permission plz) and tracking your application's responses ensures output quality and enhances overall reliability.
Key monitoring aspects include user inputs and application responses (with user permission), total number of users, number of active users, individual user usage statistics, and cost per user. Implementing user monitoring offers several benefits: it ensures output quality, identifies potential issues or areas for improvement, helps optimize resource allocation, and provides insights for product development.
There are numerous user analytics tools and internal solutions available to gain insights into user sessions. For a comprehensive solution, consider platforms like Keywords AI's User feature, which allows you to track various user metrics in one place.
Conclusion
In the rapidly evolving LLM landscape, reliability is key to standing out. By implementing a robust alert system, setting up fallbacks, and strategically increasing rate limits, developers can ensure their applications remain stable and user-friendly even under unexpected conditions. These setups, combined with effective user monitoring, form the backbone of a resilient LLM application.
While implementing these reliability measures may require initial effort, the long-term benefits are substantial. A reliable LLM application not only retains users but also builds trust and credibility in a competitive field. As you continue to develop your LLM products, prioritizing these reliability setups will position you for success, enabling your application to scale efficiently and adapt to the dynamic challenges of the AI industry.


