Keywords AI
Claude-3.5-Sonnet vs. GPT-4o: which is better?
TL;DR
- We compared Anthropic's Claude-3.5-Sonnet and OpenAI's GPT-4o across various AI tasks.
- Claude-3.5-Sonnet excels in context precision, faithfulness, and readability.
- GPT-4o is faster and better for voice AI startups due to lower latency and quicker time to first token (TTFT).
- I'll show you how to test and compare these models in just 1 minute using Keywords AI.
Intro
Anthropic released its latest flagship LLM Claude-3.5-Sonnet on Jun 20, 2024. It’s 2x faster than Claude-3-Sonnet at 20% of the cost and better performance in every mainstream LLM benchmark.
OpenAI released its most intelligent model, GPT-4o, on May 13, 2024. It’s 2x faster and 50% cheaper than GPT-4 Turbo.
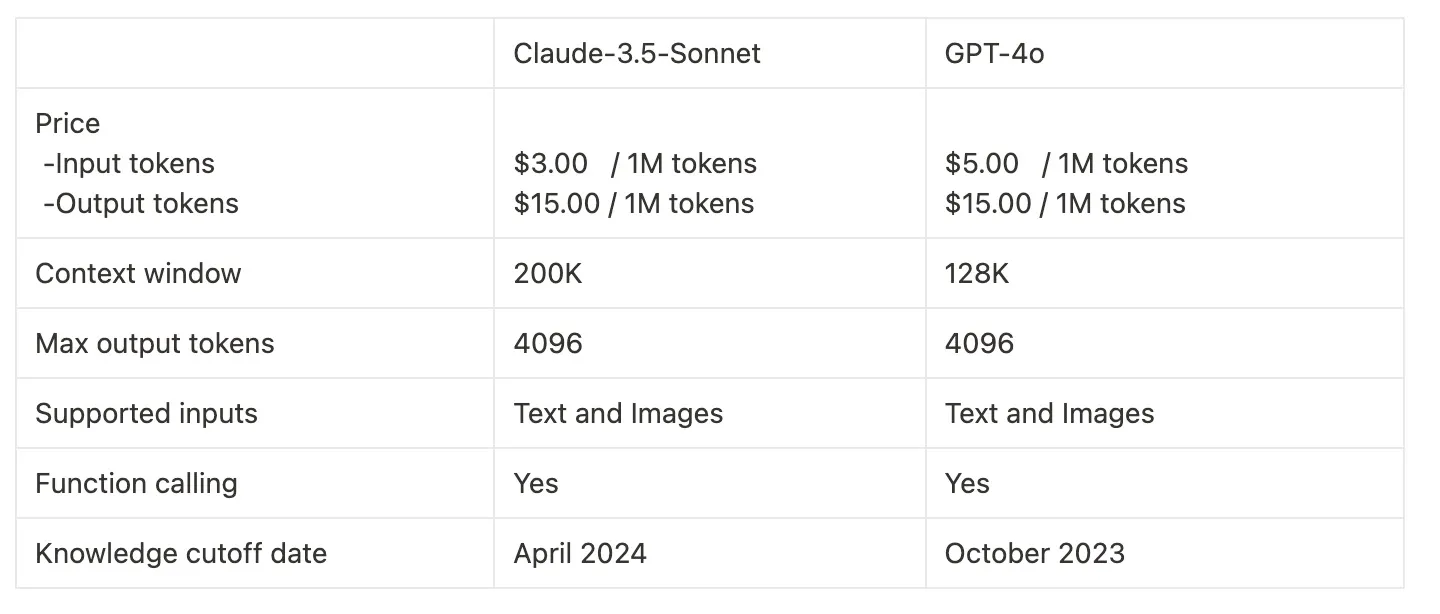
Basic Comparison
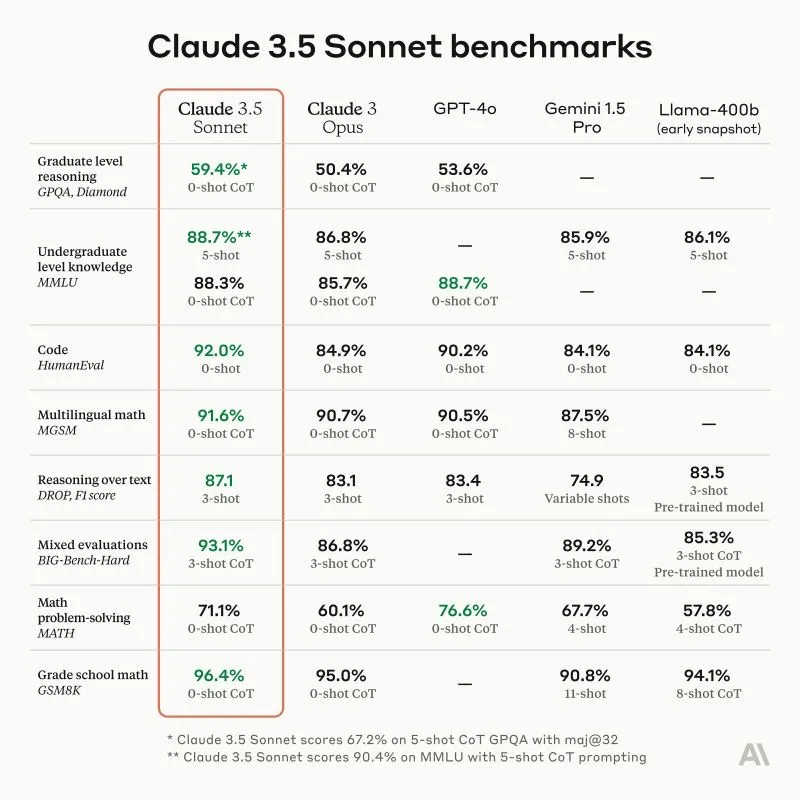
Benchmark Comparison
In benchmark evaluations, Claude 3.5 Sonnet consistently outperforms GPT-4o in areas such as graduate-level reasoning, undergraduate-level knowledge, coding, multilingual math, and reasoning over text.
While GPT-4o shows a slight advantage in math problem-solving, Claude 3.5 Sonnet generally demonstrates superior performance across most benchmarks, making it a strong choice for diverse tasks.
Test results
We still used our virtual AI company knowledge base and asked questions based on this knowledge base.
Speed Comparison
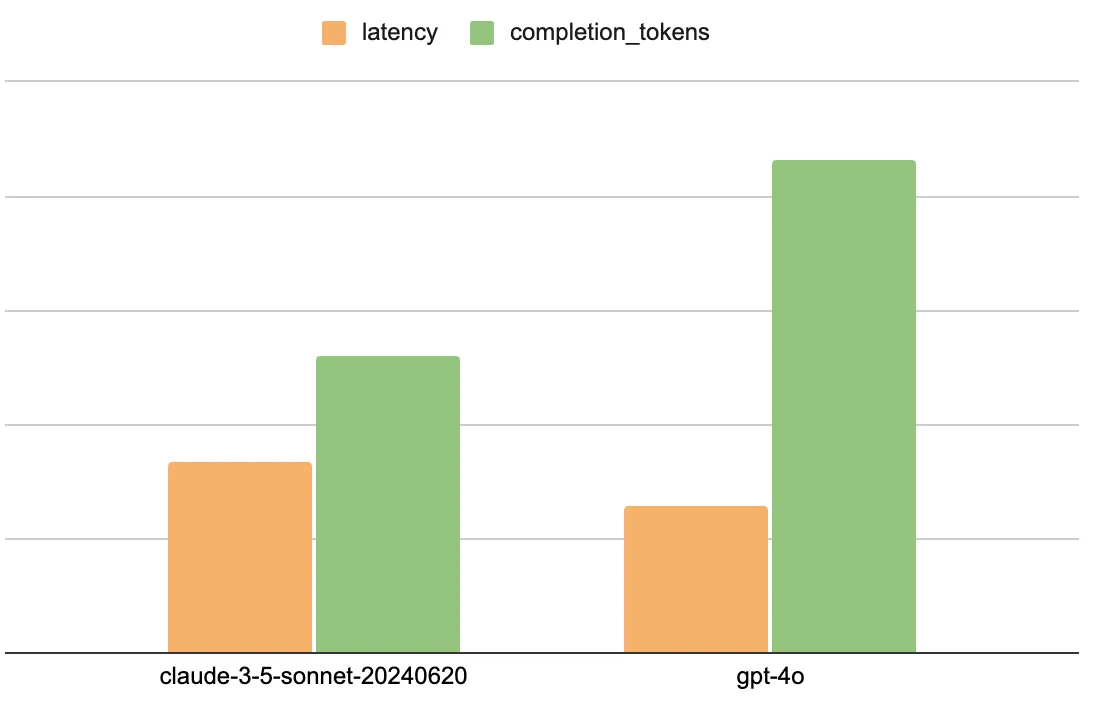
Latency & Tokens
- GPT-4o's average latency is 24% faster than Claude-3.5-Sonnet (7.5226s vs 9.3055s)
- GPT-4o even has more output tokens than Sonnet (431 tokens/request vs 260 tokens/request)
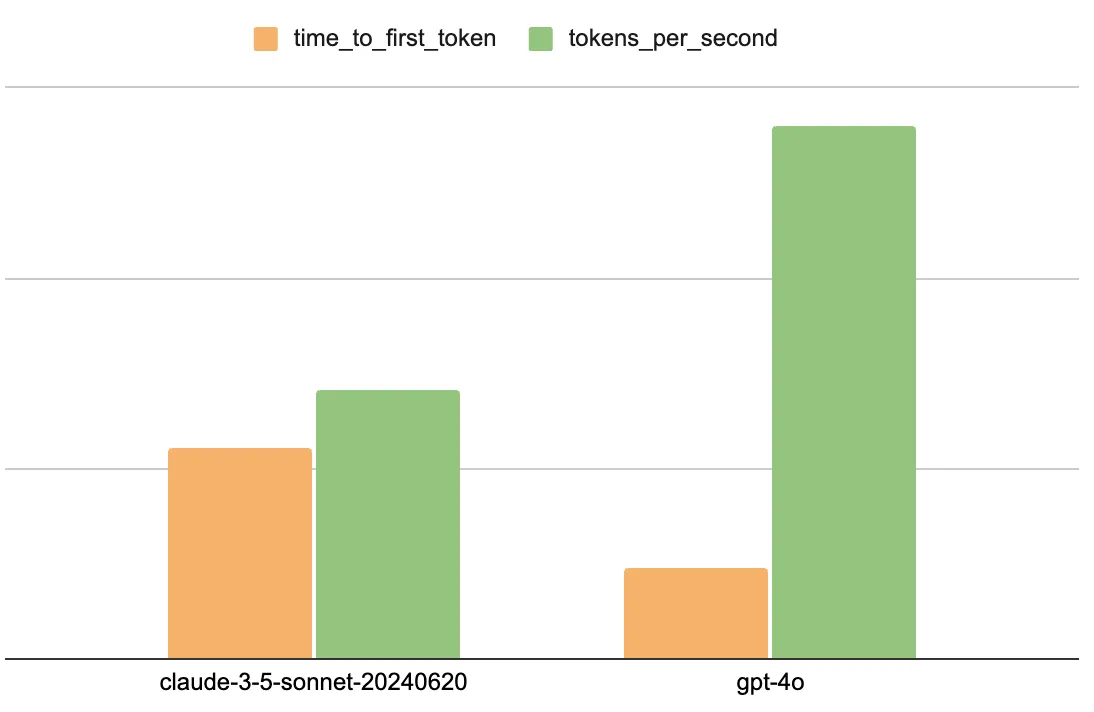
Speed & TTFT (Time to First Token)
- GPT-4o's average TTFT is 2x faster than Claude-3.5-Sonnet (0.5623s vs 1.2341s)
- GPT-4o’s average speed is also 2x faster than Claude-3.5-Sonnet (56T/s vs 28/2T/s)
Evaluation tests
We conducted evaluation tests on Keywords AI, a critical component in natural language processing tasks. The results are as follows:
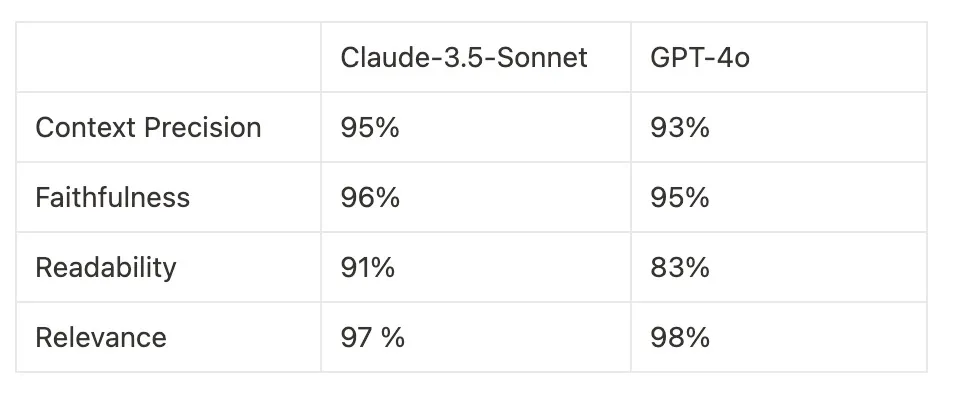
Evaluation tests showed that Claude-3.5-Sonnet outperformed GPT-4o in context precision, faithfulness, and readability, while GPT-4o was slightly better in relevance.
Coding tests
Claude-3.5-Sonnet and GPT-4o excel in coding tasks, solving basic problems and complex issues like machine learning algorithms and debugging.
Claude-3.5-Sonnet provides faster responses and detailed explanations, while GPT-4o excels in algorithmic tasks and performance optimization.
Both models effectively handle bugs and support multiple programming languages.
Conclusion
Based on our extensive testing and analysis, both Claude-3.5-Sonnet and GPT-4o excel in various AI tasks, with Claude-3.5-Sonnet leading in context precision, faithfulness, and readability.
However, GPT-4o's faster speed and time to first token (TTFT) make it a superior choice for voice AI startups where latency is critical.
As AI technology continues to evolve, choosing the right model will depend on the specific needs of each application, but both models are strong candidates for driving innovation in natural language processing and AI solutions.


